데이터 불러오기
from google.colab import drive
drive.mount('/content/drive')import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
file_path = '/content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)실습 데이터 중비~
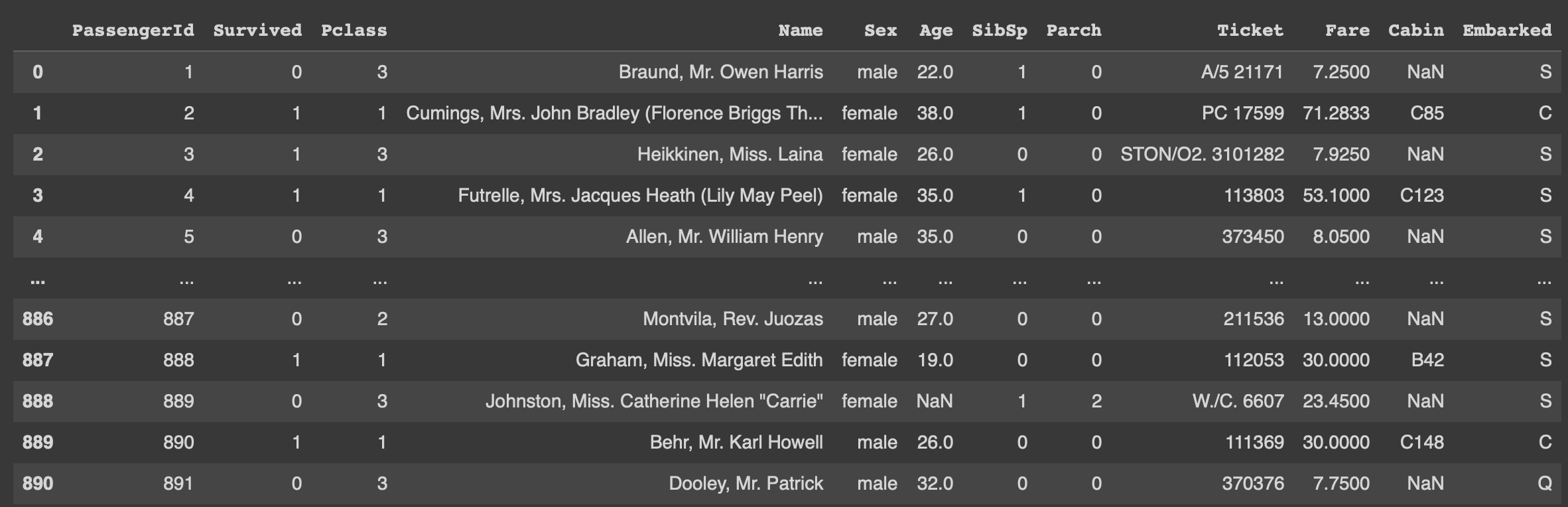
데이터프레임 살펴보기
데이터 타입 변환
df.info()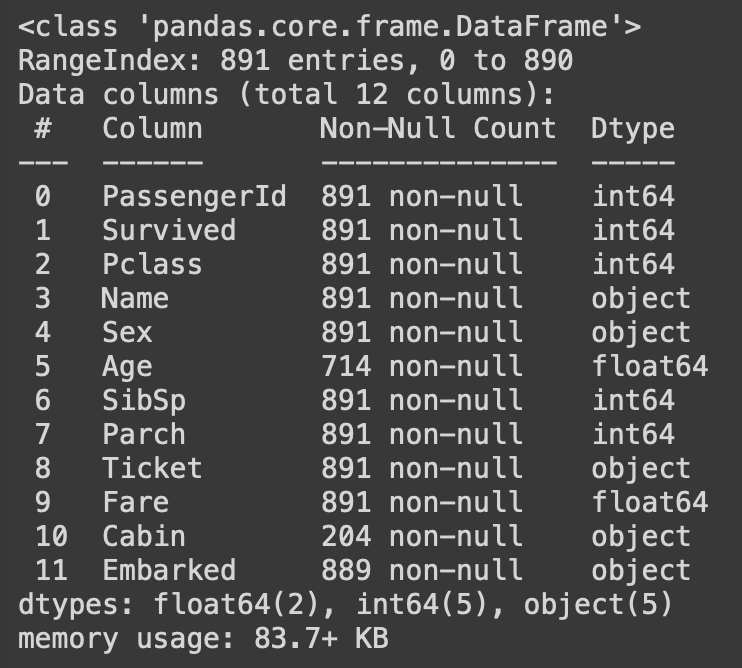
Pclass는 숫자형 int 이지만, 범주형 변수 이므로(1등급, 2등급, 3등급) astype 함수를 사용하여 변수 타입을 변환
데이터['컬럼명'] = 데이터['컬럼명'].astype(변환할타입)
- str: 문자열형
- int: 정수형
- float: 실수형
- bool: 불리언형(참/거짓)
df["Pclass"] = df["Pclass"].astype(str)데이터탐색
df.info()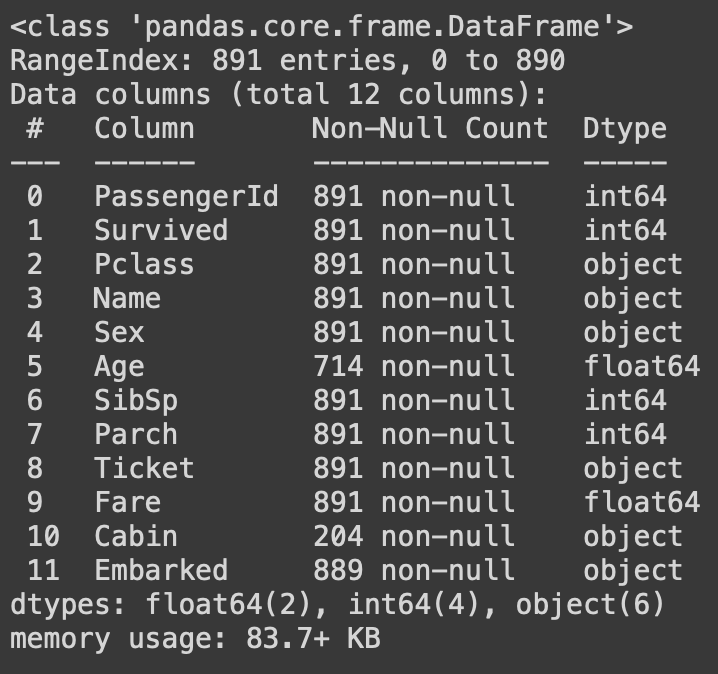
(Pclass의 데이터타입이 object, 즉 문자열로 변환된 것을 확인할 수 있다.)
또한 df.info() 결과를 보면 전체 레코드(=행, row)는 총 891개이고, 변수(=열, column)은 12개이다.
각 컬럼별 non-null count를 확인해보면 Age, Cabin, Embarked에 결측치(null)가 존재함을 확인할 수 있음
df.describe()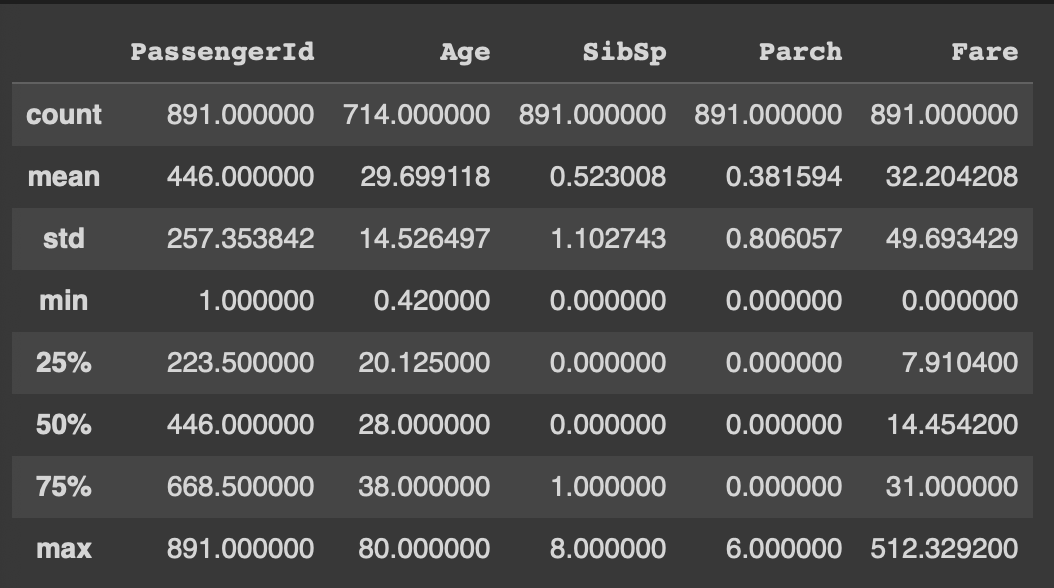
describe(): 데이터셋에 대한 EDA 수행 시 가장 많이 사용하는 함수
데이터셋의 수치형 변수에 대해서 기초통계량(갯수, 평균, 표준편차, 최솟값, 사분위수, 최댓값)을 보여준다.
df.describe(include='all')
include='all' 옵션을 추가하면 모든 변수(범주형변수 포함됨)에 대한 통계와 분포를 보여준다.
범주형 변수는 unique, top, freq 값 만을 보여준다.(기초통계량은 nan으로 표시됨)
반대로 수치형 변수의 unique, top, freq값은 nan으로 표시됨
- unique: 범주형 변수의 값의 종류
- top: 가장 많이 출현하는 값
- freq: 가장 많이 출현하는 값의 출현빈도수
기초 데이터 분석
- Pclass(좌석등급) 변수 분석
grouped = df.groupby("Pclass")
grouped.size()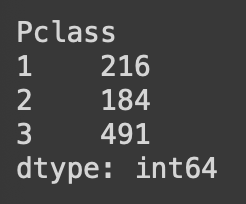
각 Pclass에 해당하는 탑승객의 빈도수를 groupby(), size()를 이용해서 구한다.
groupby() 함수를 이용하여 Pclass 별로 그루핑하고, size()를 이용하여 그룹별 행의 개수를 구한다.
3등급 객실에 탑승한 승객이 가장 많음을 알 수 있음
- Fare(요금) 변수 분석
plt.hist(df['Fare'])
plt.show()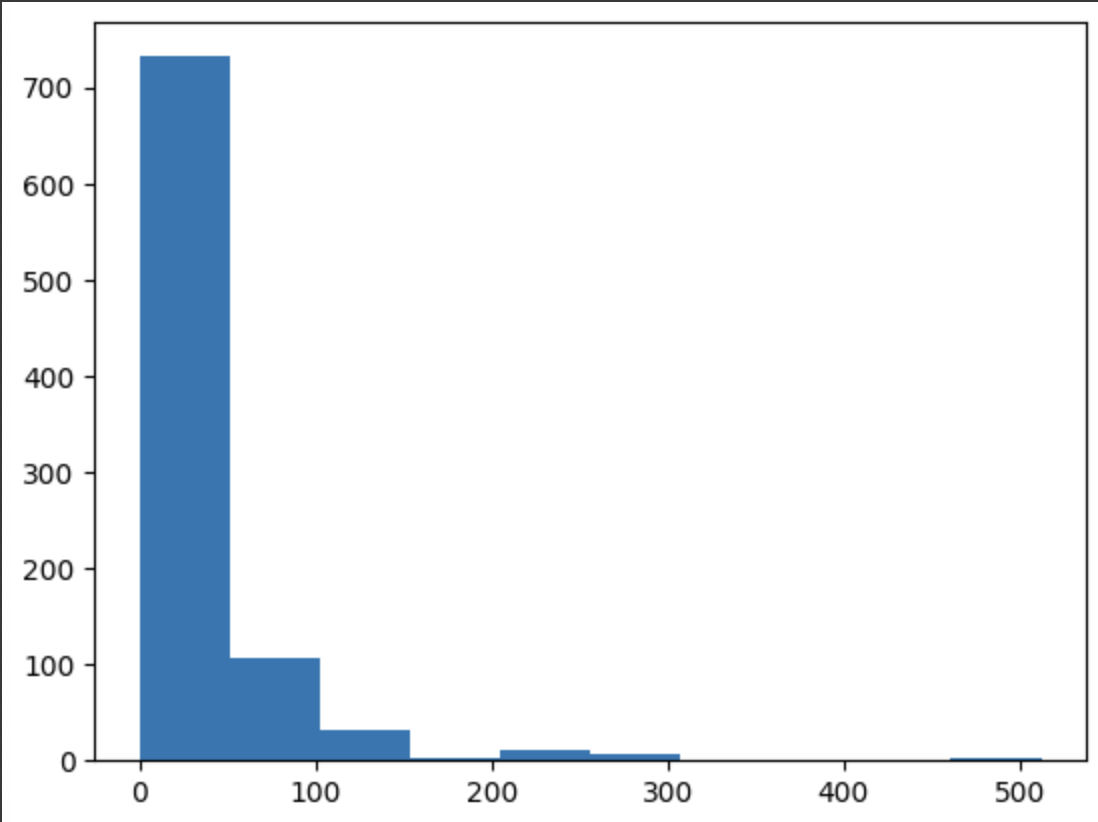
탑승객이 지불한 금액을 나타내는 Fare 변수에 대한 히스토그램 생성
#데이터 분리: 생존하지 못한 사람들의 Fare를 보여주는 data_0과 생존한 사람들의 Fare를 보여주는 data_1
data_0 = df[df['Survived'] == 0]['Fare']
data_1 = df[df['Survived'] == 1]['Fare']
#분리된 데이터셋 두 개에 대한 박스플롯 생성
fig, ax = plt.subplots()
ax.boxplot([data_0, data_1])
#축 이름 설정
ax.set_xticklabels(['Not Survived', 'Survived']) #x축에 있는 각 눈금 별 이름
ax.set_xlabel('Survival Status') #x축 전체에 대한 제목
ax.set_ylabel('Fare') #y축 전체에 대한 제목
#박스플롯 제목 설정
plt.title('Fare Distribution by Survival Status')
plt.show()
요금별 생존율의 차이가 있는지 파악하기 위해 상자수염그림(boxplot)을 이용한 데이터 시각화 수행
- 생존자들이 사망한 승객들보다 요금이 더 높지만 큰 차이는 없음
- 부가적으로 요금에 대한 이상치가 존재함을 확인할 수 있음
- Sex 변수 분석
grouped = df.groupby('Sex')
grouped.size()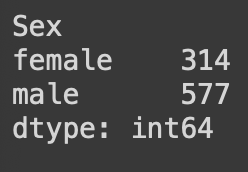
성별에 따른 빈도수 계산
#성별에 따라 데이터 분리
data_0 = df[df['Sex'] == 'female']['Survived']
data_1 = df[df['Sex'] == 'male']['Survived']
#분리한 데이터들을 Survived 여부에 따라서 그루핑
grouped_0 = pd.DataFrame(data_0).groupby("Survived")
grouped_1 = pd.DataFrame(data_1).groupby("Survived")
#각 데이터의 그루핑된 그룹별 행의 갯수 출력
print(grouped_0.size())
print(grouped_1.size())
남성이 여성보다 훨씬 많지만, 생존율은 여성 탑승객이 높음을 알 수 있다.
'빅데이터분석기사_실기 > 제1유형: 데이터 전처리' 카테고리의 다른 글
| 데이터 변환: 범주화(Categorization), 이산형화(Discretization) (0) | 2024.06.13 |
|---|---|
| 데이터 변환: 정규분포 변환 (1) | 2024.06.12 |
| 데이터 변환: Min-Max 정규화 (0) | 2024.06.12 |
| 데이터 변환: Z-표준화, Z-Score (1) | 2024.06.12 |
| 탐색적 데이터 분석 EDA: Exploratory Data Analysis (0) | 2024.06.12 |


