- 데이터의 범위가 같아지도록 변수별로 값을 비례적으로 조정하는 과정은 데이터 스케일링(Scaling)
- 데이터 스케일링의 대표적인 기법으로 표준정규화(표준화), Min-Max 정규화가 있다.
- 변수들의 측정단위나 값 범위가 다를 때 적용
실습: 정규분포를 따르는 데이터를 생성하고 살펴보기
import numpy as np
import pandas as pd
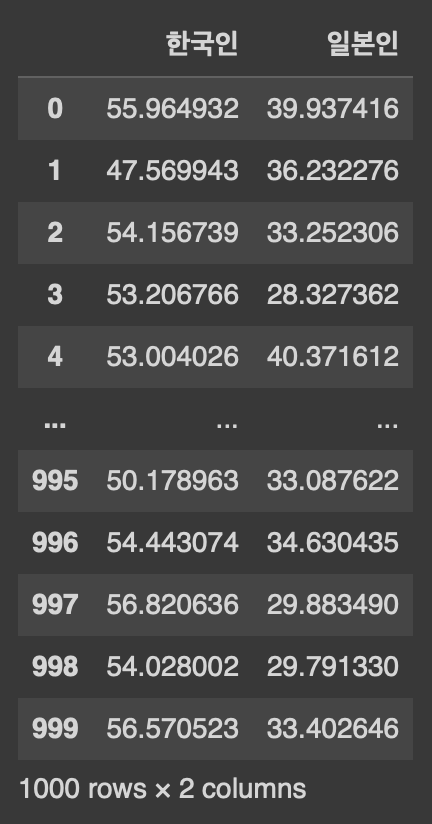
meat_consumption_korean = 5*np.random.randn(1000) + 53.9
#연간 한국인 육류쇼비량 평균 53.9, 표준편차 5의 정규분포를 따르는 1000개의 데이터 생성
meat_consumption_japanese = 4*np.random.randn(1000) + 32.7
#연간 일본인 육류소비량 평균 32.7, 표준편차 4의 정규분포를 따르는 1000개의 데이터 생성
meat_consumption = pd.DataFrame({"한국인": meat_consumption_korean, "일본인": meat_consumption_japanese})
# 한국인 컬럼에 생성된 한국인 육류소비량 데이터 넣고, 일본인 컬럼에 생성된 일본인 육류소비량 데이터 넣기
meat_consumption.head(10)
# meat_consumption 데이터프레임 앞 10개의 행 확인

import matplotlib.pyplot as plt
#한국인 육류소비량 히스토그램
plt.hist(meat_consumption_korean)
plt.xlabel('Korean Meat Consumption per Year (kg)')
plt.show()
#일본인 육류소비량 히스토그램
plt.hist(meat_consumption_japanese)
plt.xlabel('Japanese Meat Consumption per Year (kg)')
plt.show()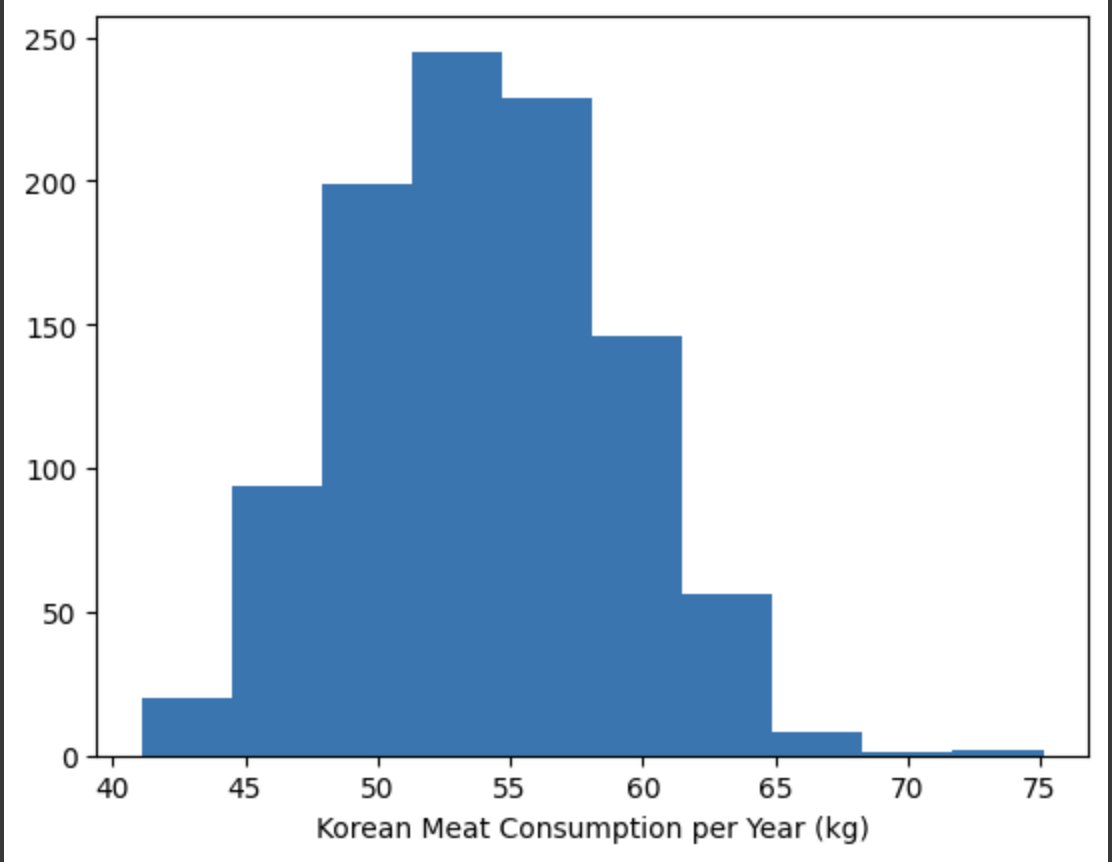

Z-표준화
- Z-score는 각 데이터 값에서 평균을 뺀 후 표준편차로 나누어 준 값(변환 후 평균=0, 표준편차=1)이다.
- (x - np.mean(x)) / np.std(x) 로 직접 계산할 수 있음
- scipy 패키지의 zscore() 함수를 사용하여 구할 수도 있음
- sckit-learn 패키지의 preprocessing을 이용하여 구할 수도 있음
방법1: numpy 이용하여 직접 계산

mid_avg = np.mean(df1["중간"])
mid_std = np.std(df1["중간"])
df1["중간_Z표준화"] = (df1["중간"] - mid_avg) / mid_std
방법2: scipy 패키지의 zscore() 함수 사용
import scipy.stats as ss
meat_consumption["한국인_정규화"] = ss.zscore(meat_consumption["한국인"])
meat_consumption["일본인_정규화"] = ss.zscore(meat_consumption["일본인"])
**방법1로 다시 구해보기**
meat_consumption["한국_직접계산"] = (meat_consumption["한국인"] - np.mean(meat_consumption["한국인"]))/np.std(meat_consumption["한국인"])
meat_consumption["일본_직접계산"] = (meat_consumption["일본인"] - np.mean(meat_consumption["일본인"]))/np.std(meat_consumption["일본인"])
값이 일치함을 확인할 수 있당.
방법3: 사이킷런 스케일러를 이용
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
meat_consumption["한국인_sk정규화"] = scaler.fit_transform(meat_consumption[["한국인"]])
scaler = StandardScaler()
meat_consumption["일본인_sk정규화"] = scaler.fit_transform(meat_consumption[["일본인"]])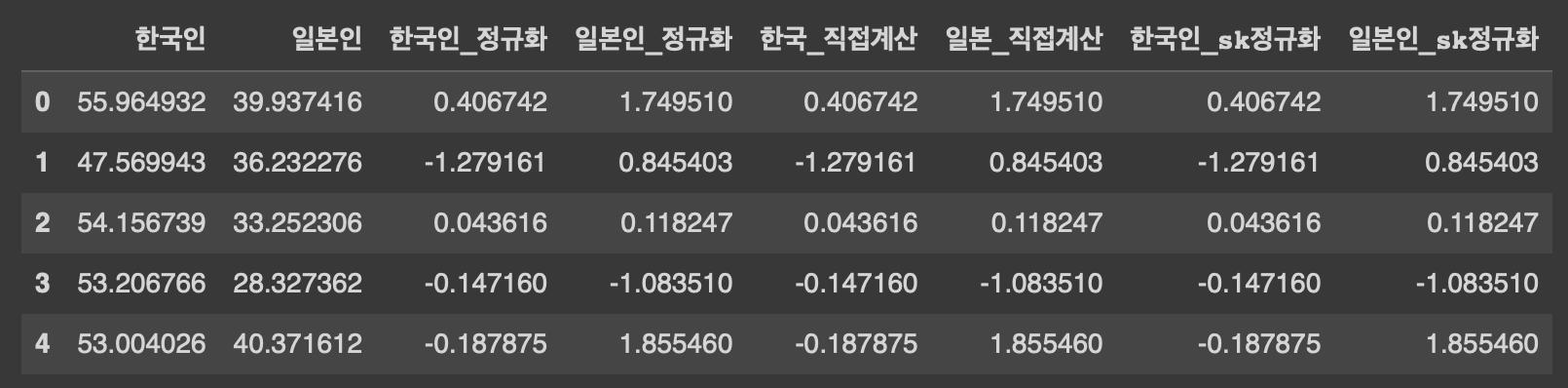
표준화된 데이터를 히스토그램을 통해 확인
plt.hist(meat_consumption["한국인_정규화"])
plt.xlabel('Korean Meat Consumption in Z-Score')
plt.show()
plt.hist(meat_consumption["일본인_정규화"])
plt.xlabel('Japanese Meat Consumption in Z-Score')
plt.show()

'빅데이터분석기사_실기 > 제1유형: 데이터 전처리' 카테고리의 다른 글
| 데이터 변환: 범주화(Categorization), 이산형화(Discretization) (0) | 2024.06.13 |
|---|---|
| 데이터 변환: 정규분포 변환 (1) | 2024.06.12 |
| 데이터 변환: Min-Max 정규화 (0) | 2024.06.12 |
| 데이터 탐색 실습 (1) | 2024.06.12 |
| 탐색적 데이터 분석 EDA: Exploratory Data Analysis (0) | 2024.06.12 |


