범주화(Categorization) / 이산형화(Discretization)
- 연속형 변수를 범주형 변수로 변환하는 작업
- "몇 개의 범주로 나눌 것인지", "어떤 기준으로 나눌지" 를 정하는 것이 중요
- 주로 조건문, cut(), qcut() 등을 사용
범주화 / 이산형화 실습
import pandas as pd
data = [["철수", 52], ["영희", 92], ["미영", 84], ["시완", 71], ["미경", 65],
["영환", 81], ["숙경", 66], ["부영", 77], ["민섭", 73], ["보연", 74]]
df = pd.DataFrame(data, columns = ["이름", "수학점수"])실습 데이터 만들기

import matplotlib.pyplot as plt
plt.hist(df["수학점수"], bins = 5, range = [50,100], rwidth = 0.9)
plt.show()히스토그램 만들어보기: 범위는 50~100, 구간은 5개로, 그리고 그래프 폭은 rwidth로 조절 (생략 시 1)

방법1: 조건을 사용해서 구간을 직접 지정
: 위의 수학점수를 가지고 A, B, C, D, F 등급을 직접 지정
- 수학 점수를 등급화 시킬 컬럼을 "등급"이라는 이름으로 생성하고, 모든 값을 0으로 초기화
- 데이터프레임의 loc함수를 사용하여 구분해줄 범위를 식으로 코딩
- 직관적인 방법, 구간 간 규칙성이 없을 시 유용
df["등급"] = 0
# 등급 컬럼 생성하고 0으로 초기화
df.loc[(df["수학점수"] < 60), "등급"] = "F"
df.loc[(df["수학점수"] >= 60) & (df["수학점수"] < 70), "등급"] = "D"
df.loc[(df["수학점수"] >= 70) & (df["수학점수"] < 80), "등급"] = "C"
df.loc[(df["수학점수"] >= 80) & (df["수학점수"] < 90), "등급"] = "B"
df.loc[(df["수학점수"] >= 90) & (df["수학점수"] <= 100), "등급"] = "A"
** loc 함수 **
- 행과 열을 레이블값을 기반으로 선택하는 함수( != iloc은 위치인덱스 기반)
[행 선택]
df.loc[0]
#인덱스가 0인 행 선택
df.loc[0:5]
#인덱스가 0부터 5까지의 행 선택 (5포함, 레이블 값 기반이기 때문)
df.loc[(df["수학점수"] >= 90)]
#"수학점수"열의 값이 90 이상인 행들 선택
[열 선택]
df.loc[:, '수학점수']
#모든 행에서 '수학점수' 열 선택
df.loc[:, ['수학점수', '영어점수']
#모든 행에서 '수학점수'와 '영어점수' 열 선택
df.loc[0:5, '수학점수']
#인덱스가 0부터 5까지의 행에서 '수학점수' 열 선택
[조건을 만족하는 행과 열 선택 및 값 할당]
- df.loc[조건, "열 이름"] = 값
- 조건을 만족하는 행들의 특정 열에 값을 할당하는 방식
방법2: cut() 함수 사용
: pd.cut(x = 데이터, bins = 경계값리스트, labels = bin이름, include_lowest = True)
- x에는 구간을 나눌 데이터 컬럼 지정
- bins에는 경계값 리스트 지정
- labels에는 각 구간의 이름 지정
- include_lowest = True는 각 구간의 낮은 경계값을 포함함 EX) a <= x < b
df["등급"] = pd.cut(x = df["수학점수"],
bins = [0,60,70,80,90,100],
labels = ["F", "D", "C", "B", "A"],
include_lowest = True)
방법3: qcut() 함수 사용
: pd.qcut(x = 데이터, q = 범주 개수, labels = 각 구간 이름)
- q에 나누고자 하는 범주개수를 지정하고, 각 범주에 균등한 수의 데이터가 채워짐
- 동일한 개수로 나누어지도록 구간을 지정할 때 유용
df["등급_qcut"] = pd.qcut(x = df["수학점수"],
q = 5,
labels = ["F", "D", "C", "B", "A"])
**실제로 동일한 개수인지 확인**
grouped = df.groupby("등급_qcut")
grouped.size()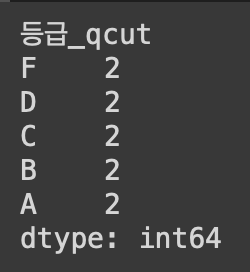
각 구간 당 동일하게 두 개씩 나누어졌당.
'빅데이터분석기사_실기 > 제1유형: 데이터 전처리' 카테고리의 다른 글
| 결측치 처리 (1) | 2024.06.13 |
|---|---|
| 데이터 변환: 차원축소 PCA, 주성분 분석 (2) | 2024.06.13 |
| 데이터 변환: 정규분포 변환 (1) | 2024.06.12 |
| 데이터 변환: Min-Max 정규화 (0) | 2024.06.12 |
| 데이터 변환: Z-표준화, Z-Score (1) | 2024.06.12 |



