결측치 처리 실습
- 실습용 타이타닉 데이터 준비
from google.colab import drive
drive.mount('/content/drive')import pandas as pd
file_path = '/content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)결측치 확인
df.info()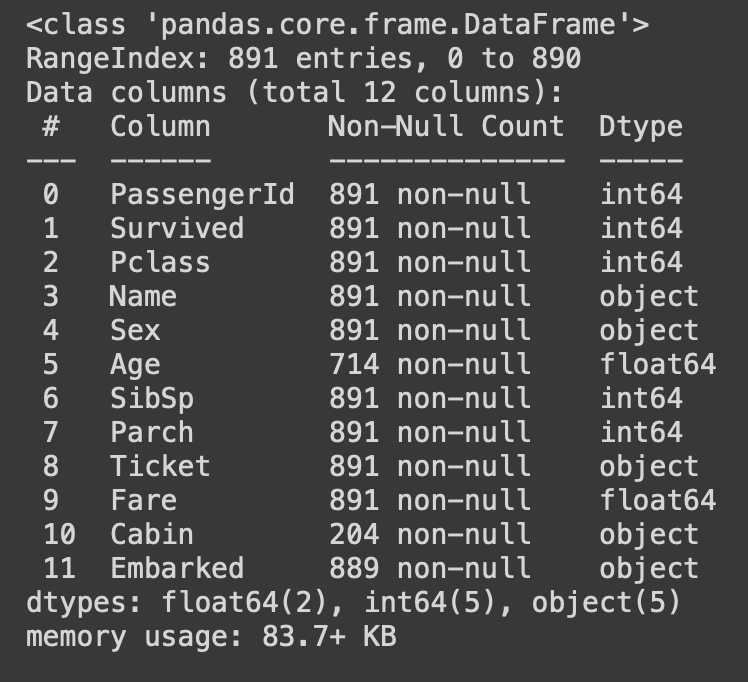
Non-Null Count 컬럼을 통해 Age, Cabin, Embarked 컬럼에 결측치가 존재함을 알 수 있당.
df.isnull().sum()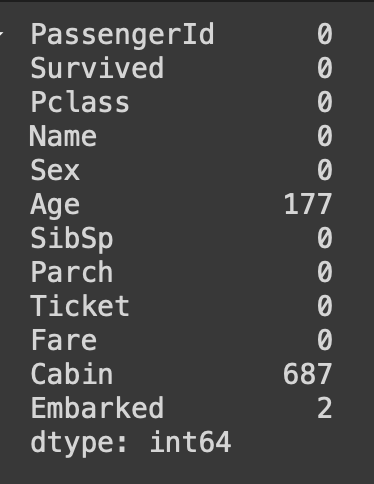
각 컬럼별 결측치 개수 확인
Age 컬럼에 177개, Cabin 컬럼에 687개, Embarked 컬럼에 2개가 존재함
결측치 제거
- 완전 분석법: 결측값이 있는 행을 삭제
print(df.shape)
df_1 = df.dropna(axis=0)
print(df_1.isnull().sum())
print(df_1.shape)
원래 891개의 행, 12개의 컬럼이 있었는데
dropna(axis=0)을 통해 결측치가 존재하는 컬럼을 제거 한 후
데이터프레임의 사이즈가 183개의 행으로 줄어든 것을 확인할 수 있당!
또한 어떤 컬럼에도 결측치가 없음을 확인할 수 있당!
결측치 대체
- 결측치를 평균값으로 대치
print(df["Age"].isnull().sum())
# 결측치를 평균값으로 대치
age_mean = df["Age"].mean()
df["Age"].fillna(age_mean, inplace=True)
print(df["Age"].isnull().sum())
Age 컬럼의 결측값을 fillna() 함수를 이용하여 age_mean(Age 컬럼의 평균값을 담은 변수)값으로 변경함!
원래 Age 컬럼에 있는 결측값 개수가 177개 였는데 대치 후 0개로 줄어들었다.
** inplace = True 옵션을 추가하면 원본 데이터프레임에 변경사항이 적용된당.**
- 결측치를 최빈값으로 대치: scipy 패키지의 mode 함수 이용
from scipy.stats import mode
print(df["Embarked"].isnull().sum())
#결측치를 최빈값으로 대치
embarked_mode = df["Embarked"].mode()
df["Embarked"].fillna(embarked_mode[0], inplace = True)최빈값이 한 개가 아니기 때문에 embarked_mode[0] 처럼 인덱스를 표기
- 결측치를 인접한 값으로 대체: ffill(직전 행의 값으로 대체), bfill(다음 행의 값으로 대체)
df["Cabin"].fillna(method='ffill', inplace= True)
df["Cabin"].fillna(method='bfill', inplace=True)
print(df["Cabin"].isnull().sum())
Cabin 컬럼에 결측치 개수가 0이 됨을 확인
- 결측치를 그룹별 평균값으로 대체
print(df.groupby("Sex")['Age'].mean())
print(df.groupby("Pclass")['Age'].mean())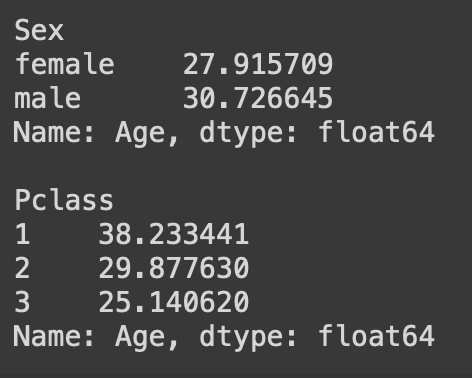
성별에 따른 Age의 평균값의 차이는 크지 않지만,
좌석등급에 따른 Age의 평균값은 차이가 큼을 확인할 수 있음
=> 결측치를 대치할 때, 좌석등급에 따라서 다른 평균값으로 대치하면 좋을듯!
df["Age"].fillna(df.groupby("Pclass")['Age'].transform('mean'), inplace = True)Pclass 별 Age 평균으로 Age 컬럼의 결측치를 대체
'빅데이터분석기사_실기 > 제1유형: 데이터 전처리' 카테고리의 다른 글
| 평활화 Smoothing (0) | 2024.06.13 |
|---|---|
| 이상치 Outlier 처리 (0) | 2024.06.13 |
| 데이터 변환: 차원축소 PCA, 주성분 분석 (2) | 2024.06.13 |
| 데이터 변환: 범주화(Categorization), 이산형화(Discretization) (0) | 2024.06.13 |
| 데이터 변환: 정규분포 변환 (1) | 2024.06.12 |



