- 파이썬의 Numpy 패키지: 데이터 분석/산술 연산에 사용하는 기본적인 패키지
* 다차원 배열 정의 및 처리를 위한 다양한 기능 제공
- 파이썬에서 기본 제공되는 자료구조인 리스트와 유사
but 배열의 크기가 커지면 성능이 떨어지는 리스트와 달리 Numpy에서는 배열의 크기가 커져도 높은 성능 보장!
*리스트와 달리 동일한 자료형만 담을 수 있다.
[Numpy 패키지 추가]
import numpy as np
#numpy 패키지를 np라는 이름으로 불러옴
[배열 만들기]
ar1 = np.array([1,2,3,4,5]) #리스트 [1,2,3,4,5]를 ndarray 객체 ar1로 생성
ar2 = np.array([[1,2,3],[4,5,6]]) #2차원 배열 생성
#ar2는 2행 3열로 이루어진 2차원 배열
print(ar1)
print(ar2)
넘파이(Numpy)의 array() 메소드
: 다양한 데이터를 N차원 배열로 변환하는 데 사용됨
numpy.array() 함수는 리스트, 튜플 또는 다른 배열과 같은 입력 데이터를 받아서 numpy 배열을 생성함
import numpy as np
# 리스트로부터 numpy 배열 생성
my_list = [1, 2, 3, 4, 5]
np_array = np.array(my_list)
print(np_array)
import numpy as np
# 2차원 리스트로부터 numpy 배열 생성
my_2d_list = [[1, 2, 3], [4, 5, 6]]
np_2d_array = np.array(my_2d_list)
print(np_2d_array)
[난수를 이용한 2차원 배열 객체 생성]
ar3 = np.random.randn(3)
ar4 = np.random.randn(2,3)
print(ar3)
print(ar4)
넘파이(Numpy)의 random.randn() 메소드
: 넘파이Numpy 패키지의 random 모듈의 randn()함수
가우시안 정규분포(표준정규분포, 평균=0 표준편차=1)를 따르는 난수 생성 함수
ex) ar3 = np.random.randn(3)
: 크기(요소 개수)가 3인 1차원 배열을 생성
*생성된 배열의 각 요소는 평균 0 , 표준편차 1인 정규분포를 따르는 난수임
ex) ar3 = np.random.randn(2,3)
: 2행 3열로 된 2차원 배열 생성
*생성된 배열의 각 요소는 평균 0 , 표준편차 1인 정규분포를 따르는 난수임
[원소를 0 또는 1로 초기화]
ar5 = np.zeros(5)
ar6 = np.ones((2,3))
print(ar5)
print(ar6)
넘파이(Numpy)의 zeros(), ones() 메소드
- zeros(n): 모든 요소가 0인 크기가 n인 1차원 배열 생성
- zeros((n,m)): 모든 요소가 0인 n행 m열로 된 2차원 배열 생성
- ones(n): 모든 요소가 1인 크기가 n인 1차원 배열 생성
- ones((n,m)): 모든 요소가 1인 n행 m열로 된 2차원 배열 생성
ex) ar5 = np.zeros(5) : 배열의 크기가 5이고 모든 요소가 0인 1차원 배열 생성
ex) ar6 = np.ones((2,3)): 2개의 행과 3개의 열로 구성되고, 모든 요소가 1인 2차원 배열 생성
[arange()와 reshape() 메소드 사용]
ar7 = np.arange(20,200,10)
ar8 = ar7.reshape(3,6)
print(ar7)
print(ar8)
넘파이(Numpy)의 arange(), reshape() 메소드
: arange() 메소드는 지정된 범위 내에서 일정한 간격을 가지는 숫자들을 생성하여 배열을 생성함
ex) ar7 = np.arange(20,200,10) : 20부터 (200-1)까지의 숫자 범위 내에서 10씩 증가하는 숫자로 이루어진 배열을 생성
=> numpy.arange(시작값,끝값,간격)
:reshape() 메소드는 원본 배열의 데이터는 변경하지 않고, 배열의 형태만 변경함
ex) ar8 = ar7.reshape(3,6) : 배열 ar7(1차원 배열)을 3*6(3행 6열)로 구성된 2차원 배열로 형태를 변경함
[인덱스 이용하기]
ar1 = np.arange(1,21,1)
# 1부터 20까지의 숫자 범위에서 1씩 증가하며 1차원 배열 생성 (원소 개수 20개)
print(ar1)
print(ar1[1])
# 인덱스는 0부터 시작 => 즉, 2번째 원소 출력
ar2 = ar1.reshape(2,10)
#배열 ar1을 2행 10열로 이루어진 2차원 배열로 형태를 변경
print(ar2)
ar2[1][1] = 100
#인덱스는 마찬가지로 0부터 시작하므로 2행 2열에 있는 원소 값을 100으로 변경
print(ar2)
print(ar2[1][0], ar2[1][1], ar2[1][2])
[배열의 산술 연산]
ar1 = np.arange(1,11,1)
#1부터 10까지 범위에서 1씩 증가하는 원소들로 이루어진 1차원 배열 생성
ar2 = ar1 + 3
#ar1의 각각의 원소에 3을 더함
ar3 = ar1 * 2
#ar1의 각각의 원소에 2를 곱함
print(ar1)
print(ar2)
print(ar3)
[배열의 통계 메소드 사용]
ar1 = np.array([[5,7,9],[-7,-6,19],[6,9,11]])
#3*3(3행 3열)로 된 2차원 배열 ar1 생성
print(ar1)
print(ar1.sum())
#배열 원소의 합계
print(ar1.mean())
#배열 원소의 평균
print(ar1.max())
#배열 원소 중 최댓값
print(ar1.min())
#배열 원소 중 최솟값
print(ar1.max(axis=0))
#배열의 각 열의 원소 중 가장 큰 값
print(ar1.max(axis=1))
#배열의 각 행의 원소 중 가장 큰 값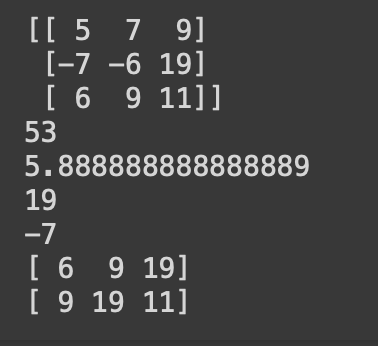
[조건식 사용 연산]
ar1 = np.array([[5,7,9],[-7,-6,19],[6,9,11]])
print(ar1 > 0)
#배열의 요소 별로 조건을 검사하여 불리언 배열을 반환함
m_count = (ar1 < 0).sum()
#조건이 맞는 True는 1로, 맞지않는 False는 0으로 처리되어 m_count에는 조건에 맞는 요소의 개수가 저장됨
print(m_count)
ar2 = np.where(ar1 < 0, 0, ar1)
# 배열 ar1에서 0보다 작은 요소는 0으로, 그렇지 않은 요소는 원본 값 그대로 유지하여 ar2 배열을 생성함
print(ar2)
넘파이(Numpy)의 where() 메소드
: numpy.where(condition, x, y)
condition에 맞으면 x로, 그렇지 않으면 y를 따라 새로운 배열을 생성하고 반환함
ex) ar2 = np.where(ar1 < 0, 0, ar1)
: ar1 배열에서 0보다 작은 요소(condition에 부합하)는 요소는 0으로 바꾸고,
0보다 크거나 같은(condition에 부합하지 않)는 요소는 ar1 배열에서의 요소 값 그대로 유지하여 새로운 배열 ar2를 생성
[배열의 정렬]
ar1 = np.array([[5,7,9],[-3,-6,19],[6,4,11]])
print(ar1)
print()
ar1.sort(0)
# sort(0)은 열 단위로 원소를 정렬
print(ar1)
print()
ar1.sort(1)
# sort(1)은 행 단위로 원소를 정렬
print(ar1)
넘파이(Numpy)의 sort(0)과 sort(1)
: sort(0) = 열 단위로 원소 정렬, sort(1) = 행 단위로 원소 정렬
* 열(행) 단위 정렬은 각 열(행)을 독립적으로 정렬하는 것
* 결과 배열은 각 열(행)의 요소들이 오름차순으로 정렬된 형태로 반환됨
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 조건에 맞는 데이터 추출하기! (0) | 2024.05.28 |
|---|---|
| 데이터(CSV, EXCEL, HTML) 불러오고 저장하기 (0) | 2024.05.28 |
| 외부 데이터 파일을 불러와 구글 코랩(colab)에서 이용하기 (0) | 2024.05.24 |
| 판다스(Pandas) 시리즈 & 데이터프레임 (0) | 2024.05.24 |
| Python Programming 기초 of 기초 (0) | 2024.05.24 |


