import pandas as pd
file_path = 'content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)
df #확인해보기자 먼저 판다스 피디로 임포트 해주고
파일경로 따로 변수에 저장해서 read_csv 함수 이용해서 titanic_train.csv 파일 불러와줍니다.

행(row) 조회
- 하나의 행 조회: 데이터프레임명[조회 할 인덱스:인덱스+1]
- 여러 개의 행 조회: 데이터프레임명[조회 할 시작인덱스:끝인덱스+1]
df[:10]인덱스 0(처음 행)부터 인덱스 9까지 총 10개의 행 조회
df[3:7]인덱스 3부터 인덱스 6까지 총 4개의 행 조회

df[3:4]인덱스 3번 행 한 개만 조회

열(column) 조회
- 하나의 열 조회: 데이터프레임['컬럼명'] / 데이터프레임.컬럼명
- 여러 개의 열 조회: 데이터프레임[['컬럼명1', '컬럼명2', ...]]
df['Survived']df.Surviveddf의 Survived 컬럼을 조회하는 두 가지 방법
df['Survived'].to_frame()데이터프레임의 형태로 조회하고 싶을 때 쓰는 함수인 .to_frame()
df[['Survived']].to_frame() 대신에 리스트로 묶으면 마찬가지로 데이터프레임 형태로 조회할 수 있다.
df[['Survived','Pclass','Name']]여러개의 컬럼을 데이터프레임 형태로 조회하고 싶을 때는 이렇게~
df에서 survived, pclass, name 컬럼만을 조회하기..
데이터를 불러올 때 애초에 pd.read_csv 에서 use_cols 인자를 사용하여
원하는 컬럼만 불러오는 방법과 다른 점은.. 애초에 불러올 때는 필요한것 외 다른 컬럼들도 불러왔었다는 것.
텍스트로 정리를 왤케 못하지???ㄷㄷㄷ 작문능력을 키워야겠어요
loc, iloc 사용하기
loc: 레이블'값'을 사용하여 조회
- 데이터프레임명.loc[행조건,열조건]
- 열조건만 입력하고 싶으면(열만 조회할때) 행조건에 : 입력 , 데이터프레임명.loc[:,열조건]
df.loc[3,]행조건만 입력한 경우: 인덱스 3번 행이 출력됨
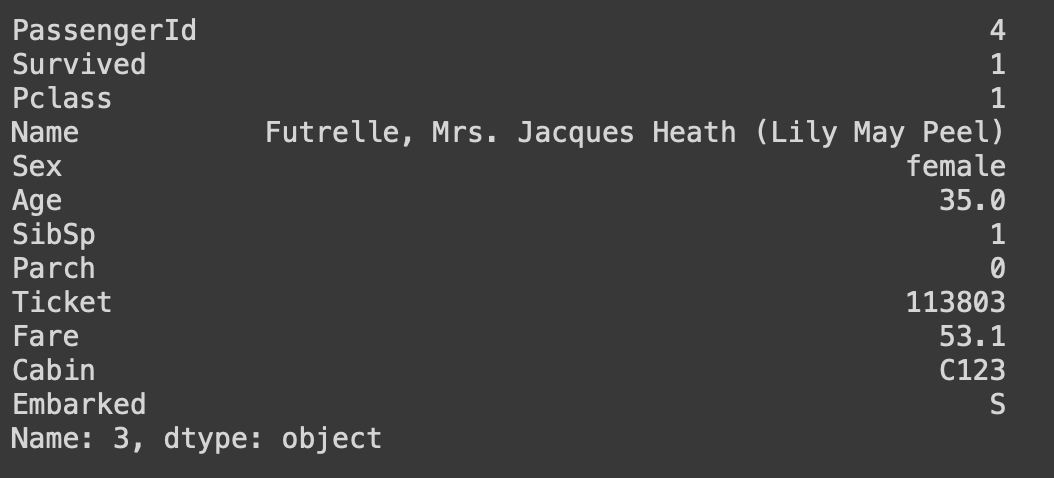
df.loc[:,'Name']열조건만 입력한 경우: Name 컬럼만 출력됨

df.loc[3,'Name']행조건과 열조건 모두 입력한 경우: 인덱스 3 행에서 Name 컬럼만 출력됨

df.loc[3:5,]행조건만 입력한 경우: 3번부터 5번행까지 조회
**왜 5번(끝인덱스)이 포함되는가?
loc은 레이블"값"을 이용해 조회하는 것이기 때문!!**
(iloc은 위치인덱스 사용)
문자열 인덱스 사용 시 끝인덱스가 포함되는 경우와 같은 것!

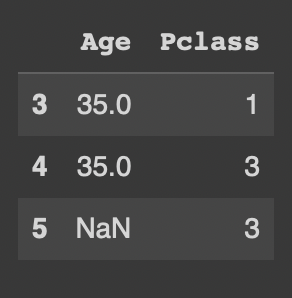
df.loc[3:5,['Age','Pclass']행조건과 열조건 모두 입력한 경우: 3,4,5번 인덱스 행들에서 age와 pclass 컬럼들만을 조회
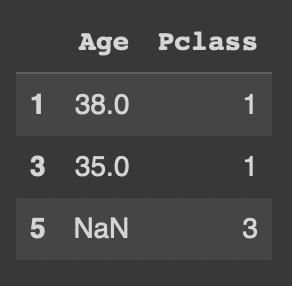
df.loc[[1,3,5],['Age','Pclass']]행조건 입력 시 범위 설정도 가능하지만 이렇게 특정 행들을 리스트로 묶어 조회할 수도 있음
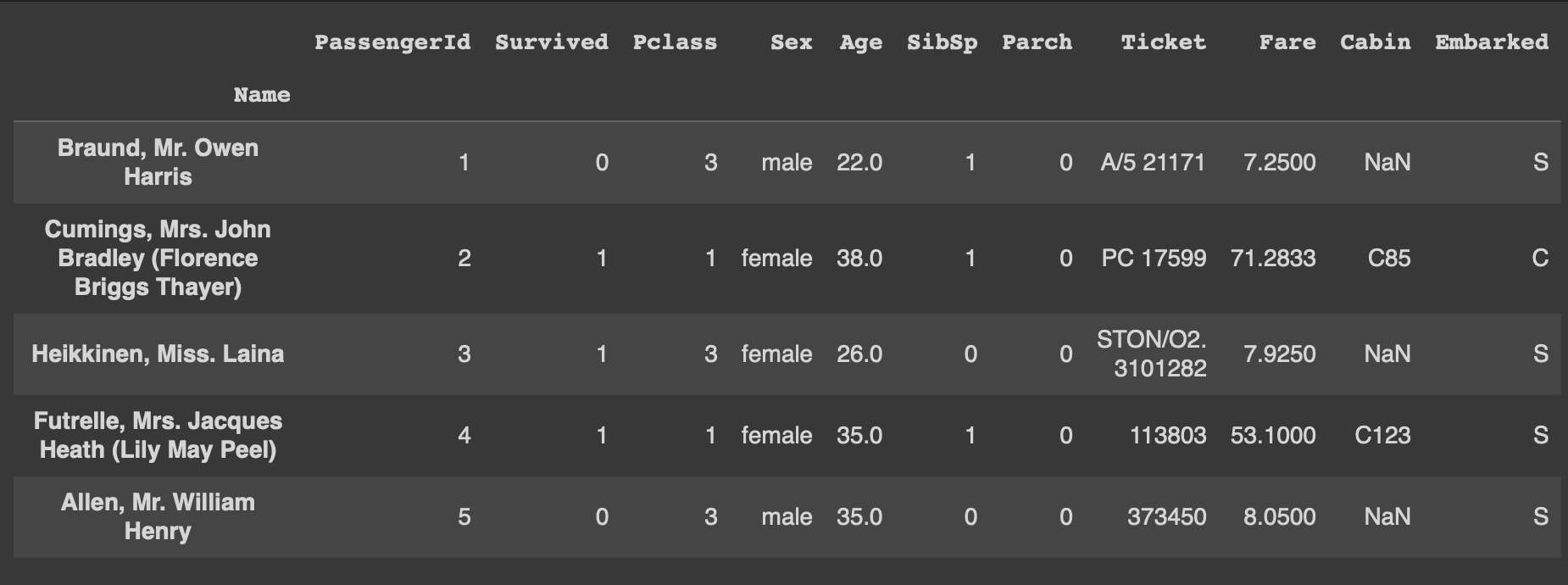
df1 = df.set_index('Name')
df1.head() #확인해보기Name 컬럼을 인덱스로 설정 -> 문자열인덱스가 생성됨
df1.loc['Heikkien, Miss. Lina']문자열 인덱스가 생성된 경우, loc 함수는 이처럼 인덱스 '값' (위치인덱스 안됨)을 넣어야 한다.
df1.loc[['Heikkien, Miss. Laina', 'Allen, Mr. William Henry'],]여러 행 보려면 이렇게 리스트로 묶어서..
df1.loc[3:5,]**이렇게 하면 오류: loc은 위치인덱스가 아닌, 레이블값!!을 이용하기 때문** 반복학습~~
iloc: 위치인덱스를 사용하여 조회
- 데이터프레임명.iloc[행인덱스조건,열인덱스조건]
- 열조건만 입력하고 싶으면(열만 조회할때) 행조건에 : 입력 , 데이터프레임명.iloc[:,열인덱스조건]
df1.iloc[3,]iloc은 위치인덱스 사용: 인덱스 3번 행을 조회
df1.iloc[:,5]iloc은 위치인덱스 사용: 인덱스 5번 열을 조회
df.iloc[3:7,]인덱스 3번부터 6번까지 총 4개의 행 조회
loc과 달리 iloc은 위치인덱스를 사용하기 때문에 끝인덱스는 포함되지 않는다.
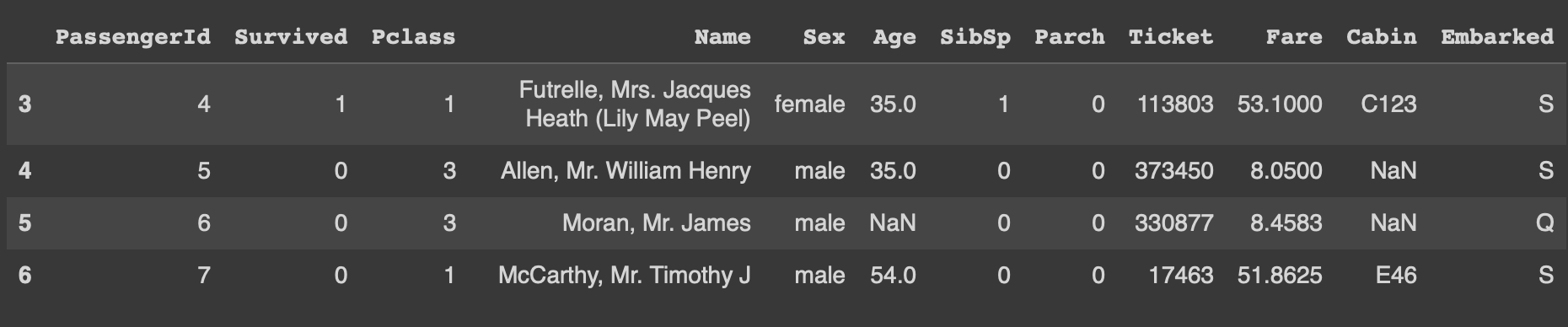
df1.iloc[3:5,2:4]3,4 위치인덱스 행들의 2,3 위치 인덱스 컬럼들만을 조회
문자열 인덱스가 설정되어 있지만 no 상관 어차피 위치인덱스쓰니까
데이터 정렬하기
- 데이터프레임명.sort_values('정렬기준컬럼명')
- 디폴트는 오름차순(ascending=True), 내림차순으로 하고 싶으면 (ascending=False) 옵션 명시
df.sort_values('Age')나이를 기준으로 오름차순 정렬됨
df.sort_values('Age',ascending=False)나이를 기준으로 내림차순 정렬됨
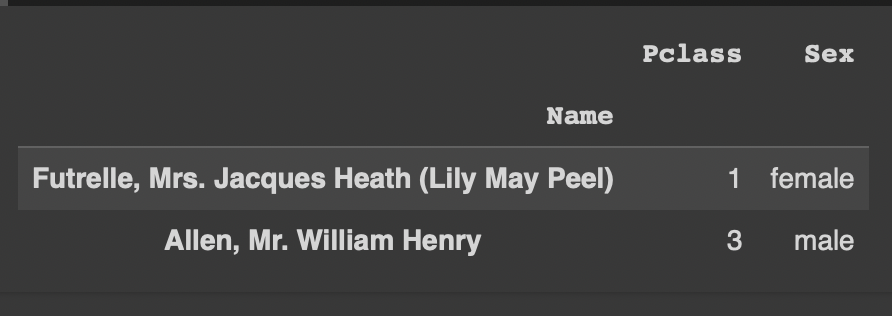
df.sort_values(['Age','Fare'], ascending=[False,True])기본적으로 Age를 기준으로 내림차순 정렬이 되는데,
Age가 같은 행들은 Fare를 기준으로 오름차순 정렬됨
특정 조건을 충족하는 데이터 추출
- 형식1: 데이터프레임명[조건식]
- 형식2: 데이터프레임명.query('조건식')
df[df['Pclass']==1]형식1: 데이터프레임명[조건식]
df에서 Pclass 값이 1인 행들만 추출하기
df.query('Pclass == 1')형식2: 데이터프레임명.query('조건식')
위와 마찬가지로 df에서 Pclass 값이 1인 행들만 추출하기
**조건식이 꼭 문자열로 표현되어야 함**
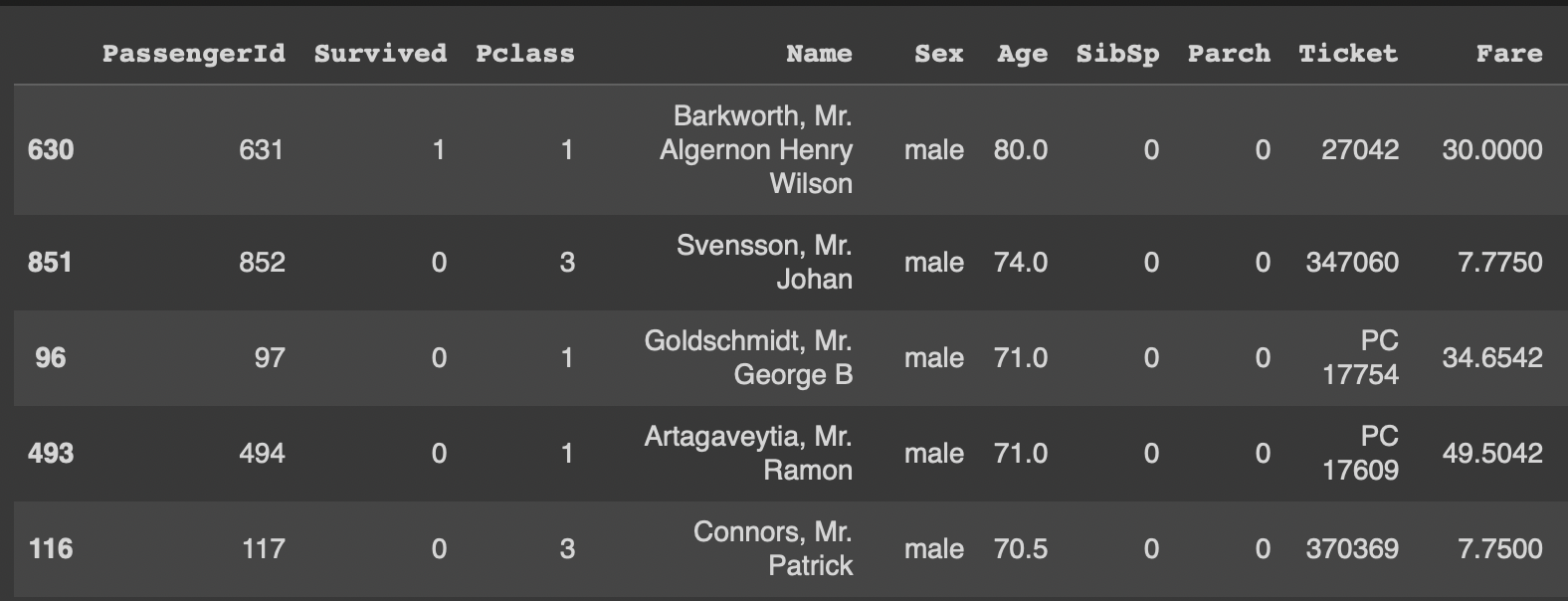
df[(df['Pclass']==1) & (df['Age']>=30)]df.query('Pclass == 1 and Age >= 30')df에서 Pclass가 1이면서 Age가 30 이상인 행들만 추출하기
**형식1에서 여러개 조건 명시하고 싶으면 대괄호 안에 괄호() 이용해서 조건문들 구분**
df[(df['Pclass'] == 1) | (df['Age'] >= 30)]df.query('Pclass == 1 or Age >= 30')df에서 Pclass가 1이거나 Age가 30이상인 행들 추출하기
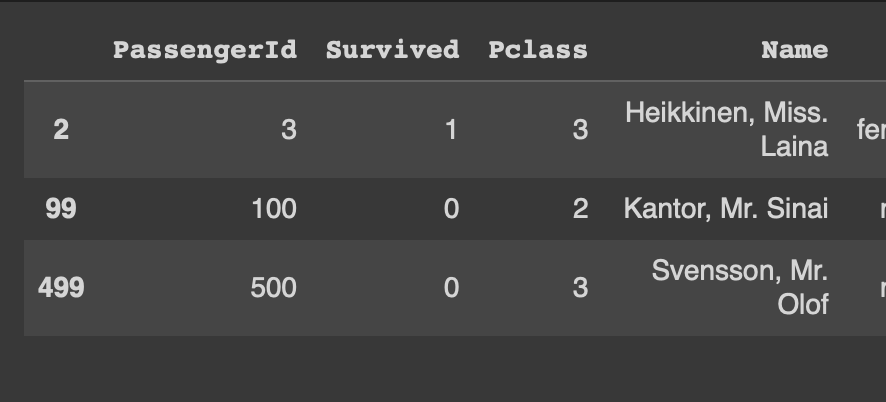
df[df['PassengerId'].isin([3,100,50])]df.query('PassengerId in [3,100,50]')df.query('PassengerId.isin([3,100,50])')df에서 PassengerId가 3,100,50 중에 있다면 그 행들을 보여줘
import random
passengerid_list = list(df['PassengerId'])
#df의 PassengerId 컬럼의 값들을 전부 passengerid_list 이름의 리스트에 저장
passengerid_sample = random.sample(passengerid_list, 10)
#random.sample 함수를 이용해서 passengerid_list에 있는 값들 중 10개를 랜덤으로 뽑아서
#passengerid_sample 이름의 리스트에 저장함
df.query('PassengerId in @passengerid_sample')
#passengerid_sample 리스트에 뽑힌 passengerId를 가진 행들을 조회**query 함수에서 문자열로 조건식을 쓸 때,
변수를 사용하려면 변수명이라는 것을 명시하기 위해 변수명 앞에 @ 사용**
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 결측값 처리하기 (0) | 2024.05.30 |
|---|---|
| 인덱스, 행, 그리고 열 (0) | 2024.05.30 |
| 데이터(CSV, EXCEL, HTML) 불러오고 저장하기 (0) | 2024.05.28 |
| 외부 데이터 파일을 불러와 구글 코랩(colab)에서 이용하기 (0) | 2024.05.24 |
| 판다스(Pandas) 시리즈 & 데이터프레임 (0) | 2024.05.24 |


