import pandas as pd
file_path = '/content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)
#실습에 사용할 데이터셋을 구글드라이브로부터 가져올게욤결측값 확인하기
- isna(): 결측값을 True로 반환
- notna(): 결측값을 False로 반환
df.info()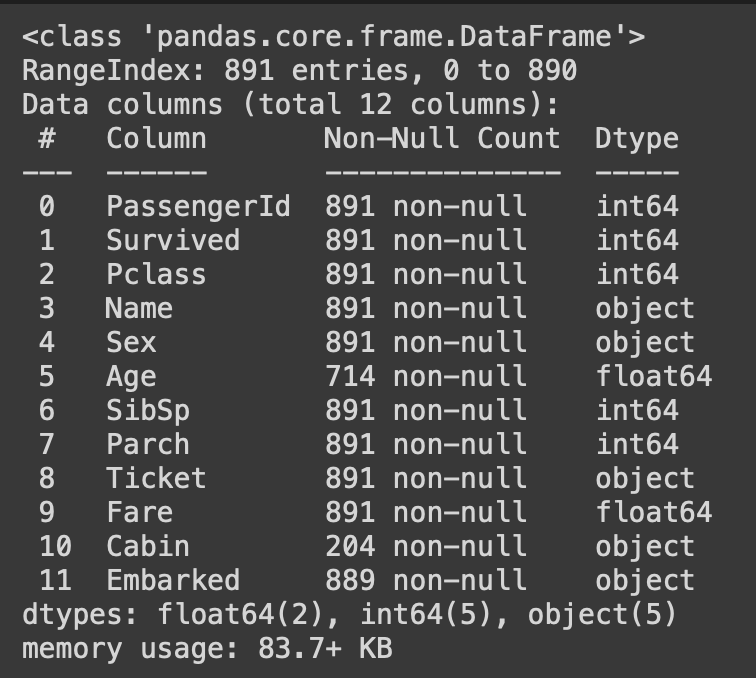
Non-Null Count는 각 컬럼 별 Null값이 아닌 행들의 개수를 보여줌
전체가 891행이라는 정보를 통해 age, cabin, embarked 컬럼에 결측치(null)가 존재함을 알 수 있당.
df.isna()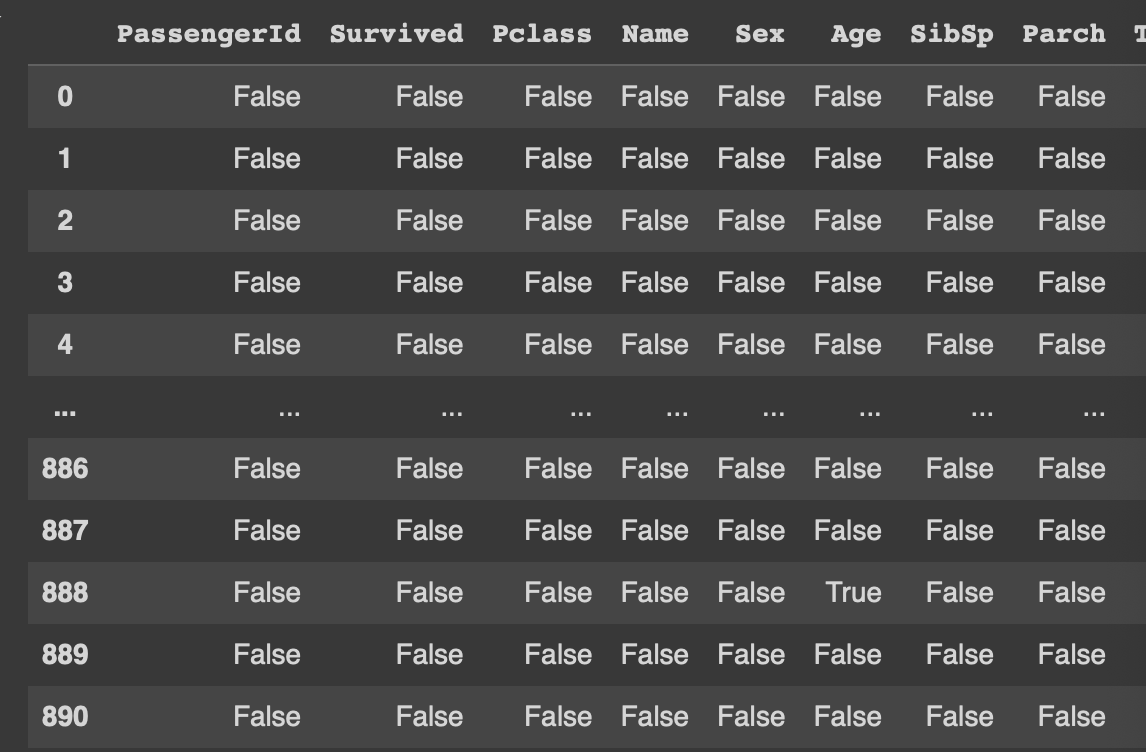
.isna()는 결측값인 경우 True를 반환하고, 결측치가 아닌 경우 False를 반환
df.isna().sum()
.isna().sum()은 각 컬럼 별 결측값이 있는 총 행의 개수가 출력됨
df[df['Age'].isna()]df.query('Age.isna()')df의 Age 컬럼 값이 결측치인 데이터만 조회
위 두가지 표현 방법으로 원하는 조건을 충족하는 데이터를 조회할 수 있음
.query방법이 훨씬 편한디
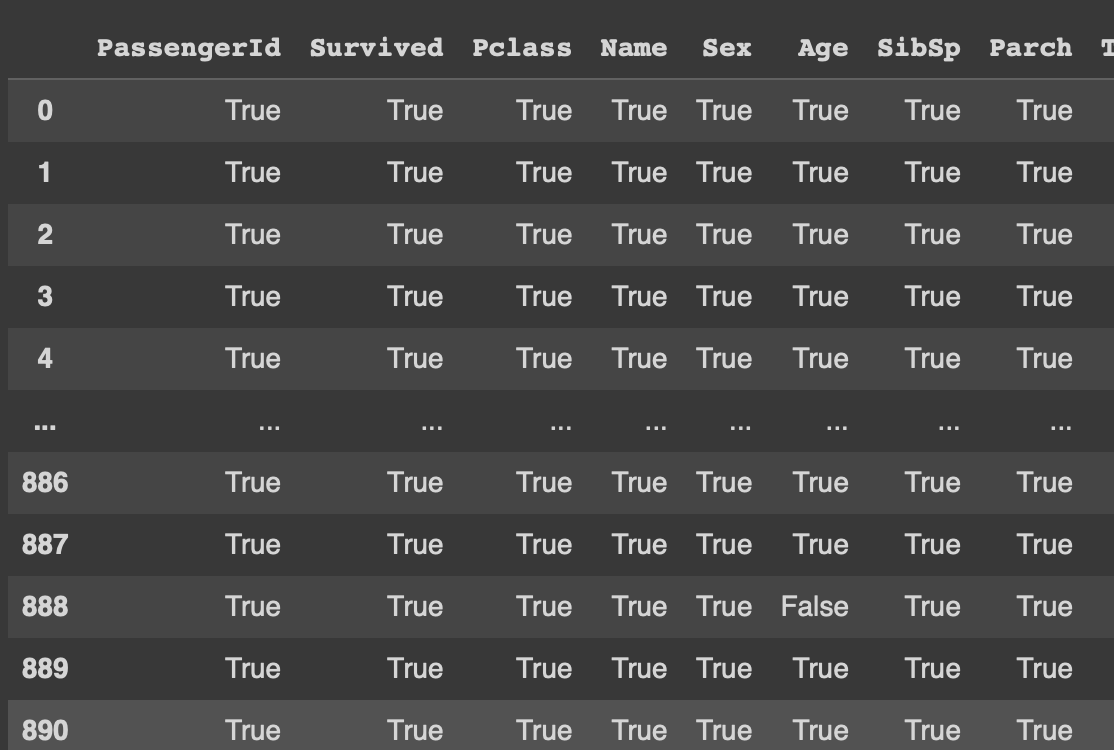
df.notna().isna()와 반대로 결측값이 False로, 결측치가 아닌 값이 True로 반환됨
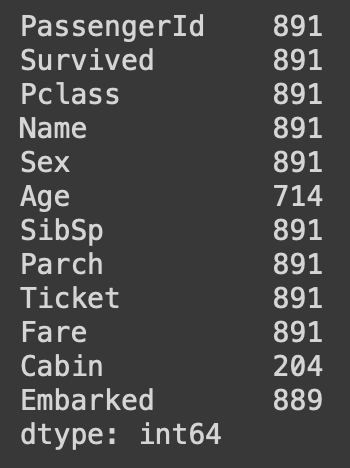
df.notna().sum()각 컬럼 별 결측값이 아닌 행의 총 개수
df[df['Embarked'].notna()]df.query('Embarked.notna()')df의 Embarked 컬럼 값이 결측치가 아닌 데이터 조회
마찬가지로 두가지 표현방법
결측값 제거하기: 데이터명.dropna()
**아무 옵션 안넣은 경우 디폴트 옵션은 axis=0 (행 삭제), how='any'(하나라도 존재하면 제거)**
- axis = 0: 행을 기준으로, 결측치가 들어있는 행 삭제
- axis = 1: 열을 기준으로, 결측치가 들어있는 열 삭제
df.dropna()결측치가 하나라도 들어있는 행이 삭제됨
df.dropna(axis = 1)결측치가 하나라도 들어있는 컬럼이 삭제됨
- how = 'any': 결측치가 하나라도 존재하는 행/열 제거
- how = 'all': 모든 값이 결측치인 행/열 제거
df.dropna(how = 'all')모든 값이 결측치인 행이 제거됨
- subset 옵션에는 특정 행/열에 결측치가 있는 경우 그 열/행을 삭제하고 싶을 때 사용
df.dropna(subset=['Cabin','Age'])Cabin이나 Age 컬럼에 결측치가 있는 행을 삭제
결측값 대치하기
- 데이터 전체의 결측값을 특정 값으로 변경: 데이터명.fillna(대치할값)
- 특정 컬럼의 결측값을 측정 값으로 변경: 데이터명['컬럼명'].fillna(대치할값)
- 결측값을 바로 위(전) 행의 값과 동일하게 변경: 데이터명.fillna(method='ffill')
- 결측값을 바로 아래(후) 행의 값과 동일하게 변경: 데이터명.fillna(method='bfill')
df.fillna(-1)df의 모든 결측값을 -1로 대치!
하지만 반영안됨, ㄹㅇ로 데이터셋에 변경 내용 반영하려면 덮어씌워줘야함
df1= df.copy()
df1['Age'] = df1['Age'].fillna(-1)df1의 age 컬럼에 있는 결측치를 모두 -1로 변경함 (반영됨)
df1 = df.copy()
df1['Age'] = df1['Age'].fillna(round(df1.['Age'].mean()))df1의 age 컬럼에 있는 결측치를 (age컬럼의 평균값을 반올림한 값)으로 변경함 (반영됨)
df.fillna(method = 'ffill')method='ffill'은 결측치 앞(전) 행의 값으로 대치됨
df.fillna(method = 'bfill')method = 'bfill'은 결측치 뒤(후) 행의 값으로 대치됨
* 마찬가지로 반영하려면 덮어씌워라~
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 날짜 데이터 (0) | 2024.06.04 |
|---|---|
| 데이터 타입 변환하기 (0) | 2024.05.30 |
| 인덱스, 행, 그리고 열 (0) | 2024.05.30 |
| 조건에 맞는 데이터 추출하기! (0) | 2024.05.28 |
| 데이터(CSV, EXCEL, HTML) 불러오고 저장하기 (0) | 2024.05.28 |



