import pandas as pd
file_path = '/content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)
#실습에 사용할 데이터셋을 구글드라이브에서 가져올게용~데이터 타입 확인하기
- .dtypes: 각 컬럼의 데이터 타입을 시리즈 형태로 출력합니다.
df.dtypes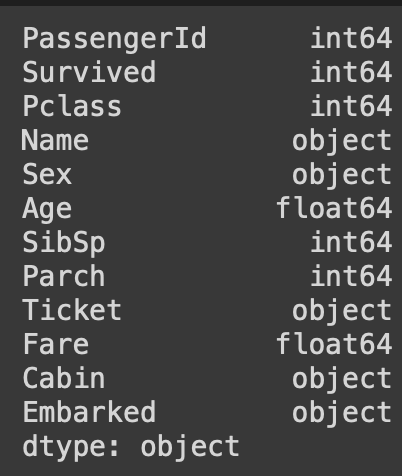
* int: 정수, object: 문자열, float: 실수
- 특정 데이터타입을 가진 데이터만 추출: 데이터명.select_dtypes('데이터타입')
df.select_dtypes('int')int(정수)에 해당하는 데이터만 불러오기
df.select_dtypes('object')문자열에 해당하는 데이터만 불러오기
데이터타입 변환하기
- 데이터명['컬럼명'].astype(변환할데이터타입)
df1 = df.copy()
df1['PassengerId'] = df1['PassengerId'].astype(str)PassengerId 컬럼의 데이터는 원래 int임
하지만 더하고빼는 등 연산을 할게 아니기 때문에 문자열로 변경하고자함
이렇게 덮어 씌워줘야 변경 내용이 데이터셋에 반영됨ㅋ
df['Age'].astype(int)이번엔 원래 실수형인 Age 컬럼의 데이터를 정수형으로 변경하고자 함
하지만 에러가 뜬다
왜? Age 컬럼에는 결측치가 존재하는데 결측치를 정수형으로 변환할 수 없기 때문..
그렇다면 결측치에 대한 처리를 먼저 해줘야겠지?!
df1 = df.copy()
df1['Age'] = df1['Age'].fillna(-1).astype(int)먼저 Age 컬럼의 결측치를 전부 -1로 대치하고 데이터타입 변환을 실행한다.
이렇게 덮어씌워줘야~ 변경 내용이 데이터셋에 반영됨
** 만약에 정수형으로 데이터 변환은 하고싶은데 결측치를 -1로 바꾸지 않고 그냥 결측치로 냅두고 싶으면??**
import numpy as np
df1 = df.copy()
df1['Age'] = df1['Age'].fillna(-1).astype(int).replace(-1, np.nan)먼저 Age 컬럼의 결측치를 전부 -1로 대치하고 정수형으로 데이터타입 변환 실행
그 이후 numpy의 nan을 이용하여 Age 컬럼의 -1값들을(원래 결측치였던것들) 다시 nan(결측치)로 변경해주면됨
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 데이터가공: apply, map, 문자열 다루기 (0) | 2024.06.11 |
|---|---|
| 날짜 데이터 (0) | 2024.06.04 |
| 결측값 처리하기 (0) | 2024.05.30 |
| 인덱스, 행, 그리고 열 (0) | 2024.05.30 |
| 조건에 맞는 데이터 추출하기! (0) | 2024.05.28 |



