from google.colab import drive
drive.mount('/content/drive')import pandas as pd
file_path = '/content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)실습에 필요한 데이터 파일을 준비해보아요
apply 함수
- 사용자 정의 함수를 데이터에 적용하고 싶을 때 사용
- .apply(함수이름, axis = 0/1)
def pclass_sibsp(x):
if x['Pclass'] == 1 and x['SibSp'] == 1:
return 1
else:
return 0
df1 = df.copy()
df1['pclass_sibsp_filter'] = df1.apply(pclass_sibsp, axis = 1)[pclass_sibsp 함수 정의]
데이터프레임 x를 받았을 때, 이 x의 Pclass 컬럼 값이 1이면서 SibSp컬럼값도 1이면 1을 반환
아니면 0을 반환
[df1에 새로운 컬럼 pclass_sibsp_filter 생성]
그 값들은 위에서 정의한 pclass_sibsp함수를 행 방향(axis=1)으로 적용해서 생성됨
**왜 행 방향(axis=1)으로 적용해야 할까?**
pclass_sibsp함수는 두개의 컬럼 Pclass와 SibSp 를 동시에 접근해야 하기 때문에 각 "행"에 적용되어야 하기때문
import numpy as np
def adult(x):
if x >= 19:
return 1
elif x < 19:
return 0
else:
return np.nan[adult 함수 정의]
x값이 19보다 크면 1 리턴, 작으면 0 이런, 그 외(ex.null)일 경우 nan(null)리턴
df1['adult_yn'] = df1['Age'].apply(adult)axis 옵션을 명시하지 않으면 디폴트로 열 방향(axis=0), adult함수는 Age열에 적용되므로 열 방향으로 적용
간단한 함수는 lambda를 이용하여 구현
df1['pclass_sibsp_lambda'] = df1.apply(lambda x: 1 if x['Pclass'] == 1 and x['SibSp'] == 1 else 0, axis=1)위에 있는 pclass_sibsp 함수를 lambda로 구현
map 함수
- 값을 특정 값으로 치환하고 싶을 때 사용
- 데이터명['컬럼명'].map(매핑딕셔너리)
gender_map = {'male': '남자', 'female': '여자'}
#매핑 딕셔너리 생성
df1['Sex_kr'] = df1['Sex'].map(gender_map)매핑 딕셔너리인 gender_map에 쓰여있는 대로,
df1의 Sex 컬럼에 있는 'male'은 '남자'로 바뀌고, 'female'은 '여자'로 바뀐다.
문자열 다루기
- .str.contains('문자열'): 문자열을 포함하고 있는지 유무
- .str.replace('기존문자열', '대치문자열'): 문자열 대치
- .str.split('기준문자열', expand = True/False, n = 개수): 기준 문자열을 기준으로 n번 쪼개서 열에 나눠 담기
- .str.lower(): 소문자로
- .str.upper(): 대문자로
.str.contains('문자열')
df2 = df.copy()
df2['Name'].str.contains('Mrs')각 행의 Name컬럼에 문자열 'Mrs'를 포함하고 있니?
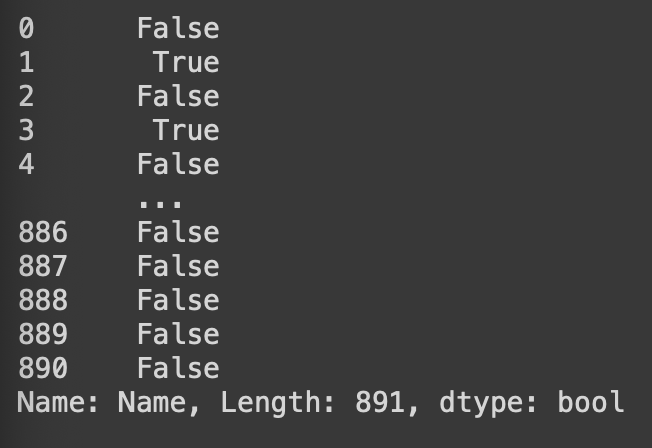
df2[df2['Name'].str.contains('Mrs')]df2.query('Name.str.contains("Mrs")')특정 조건(Name 컬럼에 Mrs를 포함하고 있는가)을 충족한 데이터 추출
동일한 결과, 두가지 표현 방식
.str.replace('기존문자열', '대치문자열')
df2['Name'] = df2['Name'].str.replace(',','')Name컬럼에 있는 컴마(,)를 사라지게 함('')
.str.split('기준 문자열', expand=True/False, n = 개수)
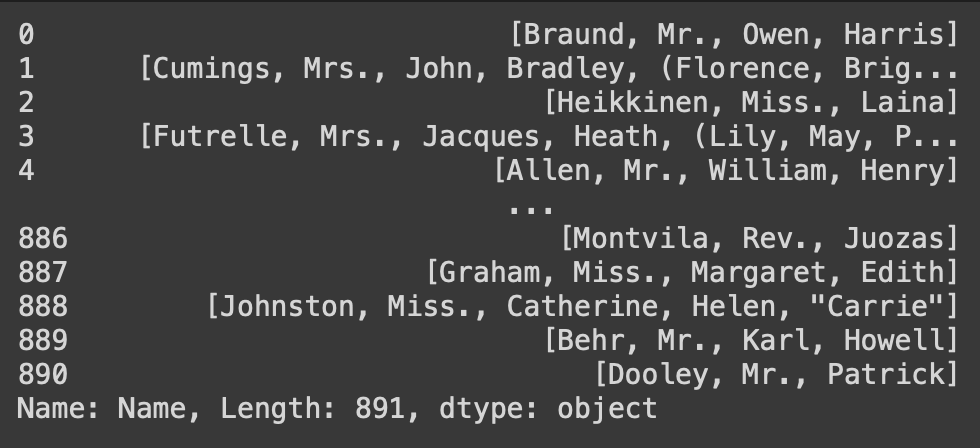
df2['Name'].str.split(' ')공백 ' '을 기준으로 각 행의 Name컬럼의 문자열을 쪼개서 리스트에 담음
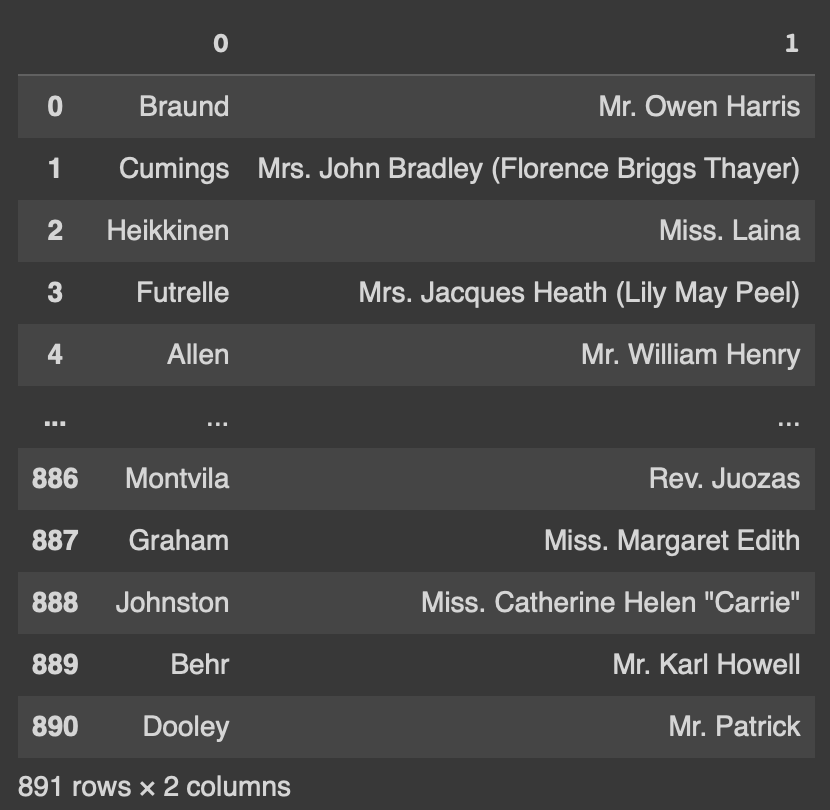
df2['Name'].str.split(' ',expand = True, n=1)expand = True로 하면 split한 문자열들을 n+1개의 열로 쪼개어 담음
이 경우 Name컬럼의 값(문자열)은 첫번째로 쪼개진 값과 그외나머지, 총 두개의 열로 나뉘어 담긴다.
.str.lower()
.str.upper()
df2['Name'].str.lower()df2의 Name컬럼의 문자열을 전부 소문자로
df2['Name'].str.upper()df2의 Name컬럼의 문자열을 전부 대문자로
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 데이터 분포와 통계량 (0) | 2024.06.11 |
|---|---|
| 데이터 결합 (0) | 2024.06.11 |
| 날짜 데이터 (0) | 2024.06.04 |
| 데이터 타입 변환하기 (0) | 2024.05.30 |
| 결측값 처리하기 (0) | 2024.05.30 |



