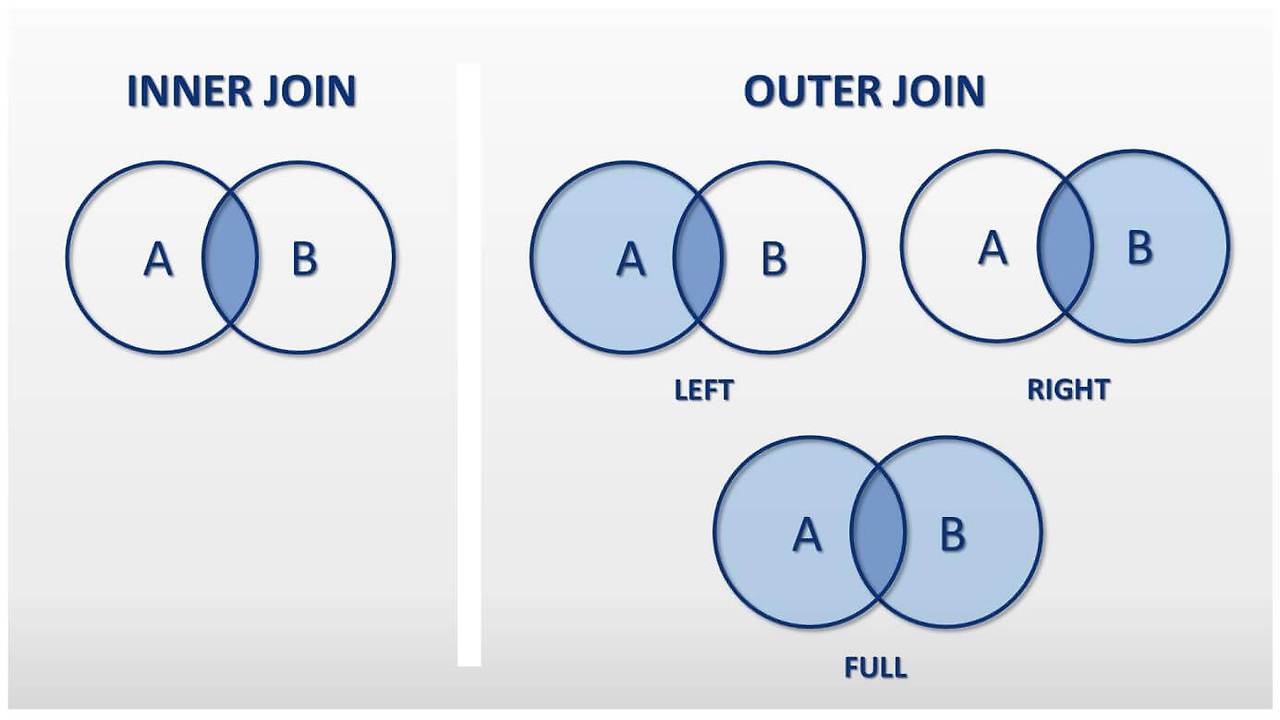
- 두 개의 데이터를 특정 컬럼을 기준으로 결함
- 결합 방법
- pd.merge(데이터1, 데이터2, on='기준 컬럼', how = '결합방법')
import pandas as pd
customer = pd.DataFrame({'id': [i for i in range(1,7)],
'name' : ['민준', '서연', '서준', '도현', '지윤', '채원']
'age' : [15,30,40,20,23,31]})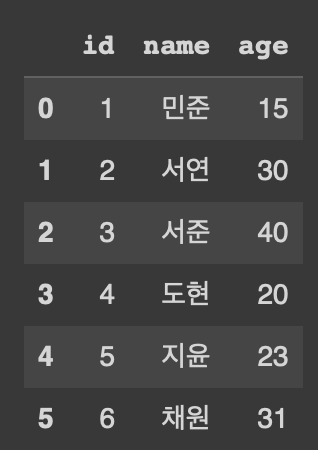
orders = pd.DataFrame({'id' : [1,1,2,3,3,4,5,7,7,7],
'item' : ['사과','체리','바나나','사과','바나나','바나나','체리','사과','체리','바나나'],
'quantity' : [1, 2, 1, 1, 3, 2, 2, 3, 2, 1]})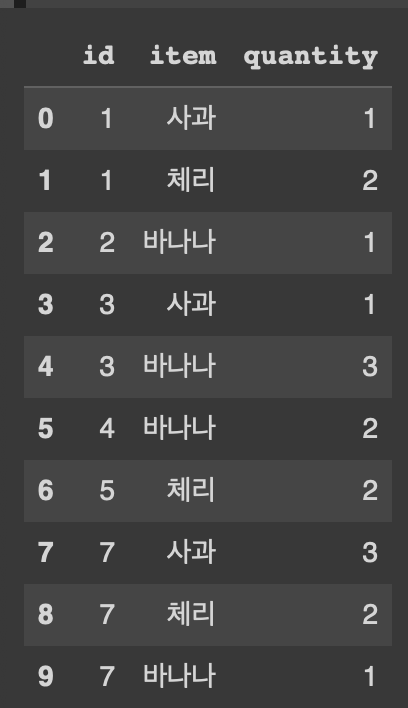
INNER JOIN
pd.merge(customer, orders, on='id', how = 'inner')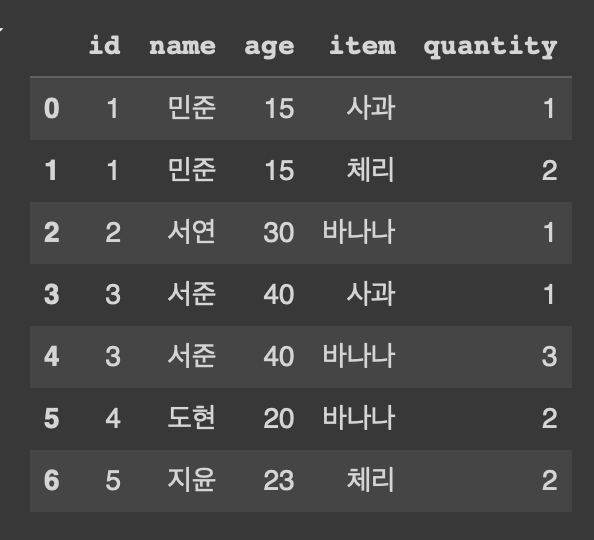
customer의 id컬럼 값과 orders의 id컬럼값이 일치하는 데이터들만 추출(교집합)
LEFT OUTER JOIN
pd.merge(customer, orders, on='id', how='left')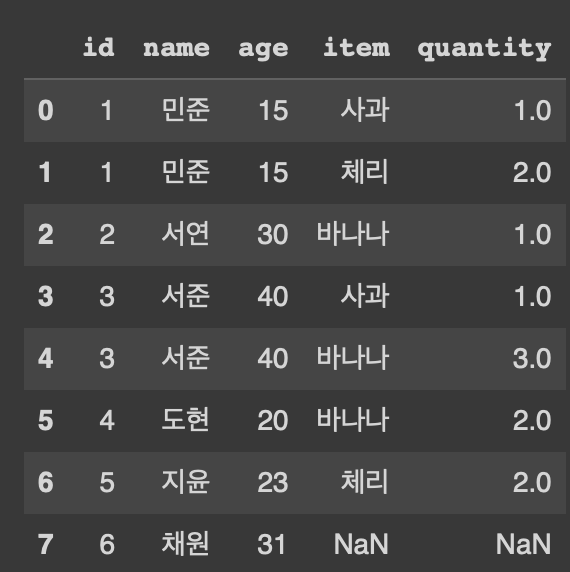
customer의 데이터들은 전부 추출되고, id컬럼값을 기준으로 연결되는 orders의 데이터들이 추출되고 연결안되면 Null로
RIGHT OUTER JOIN
pd.merge(customer, orders, on='id', how = 'right')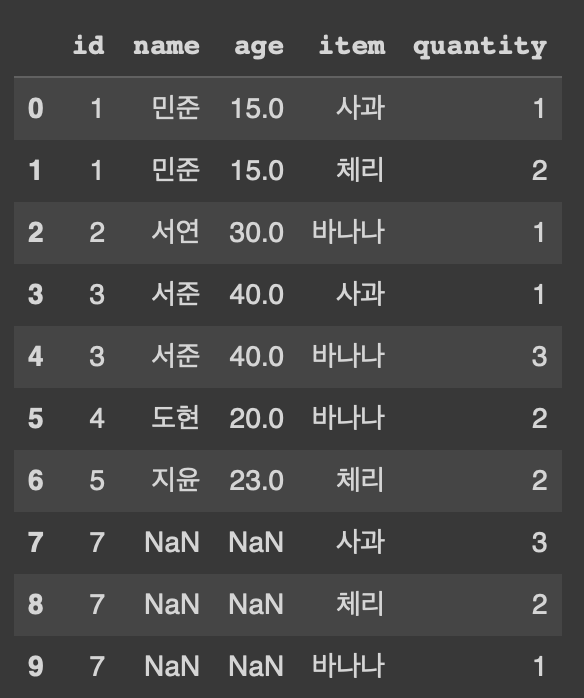
orders의 데이터들은 전부 추출되고, id컬럼값을 기준으로 연결되는 customer의 데이터들이 추출되고 연결안되는건 null로
FULL OUTER JOIN
pd.merge(customer, orders, on='id', how='outer')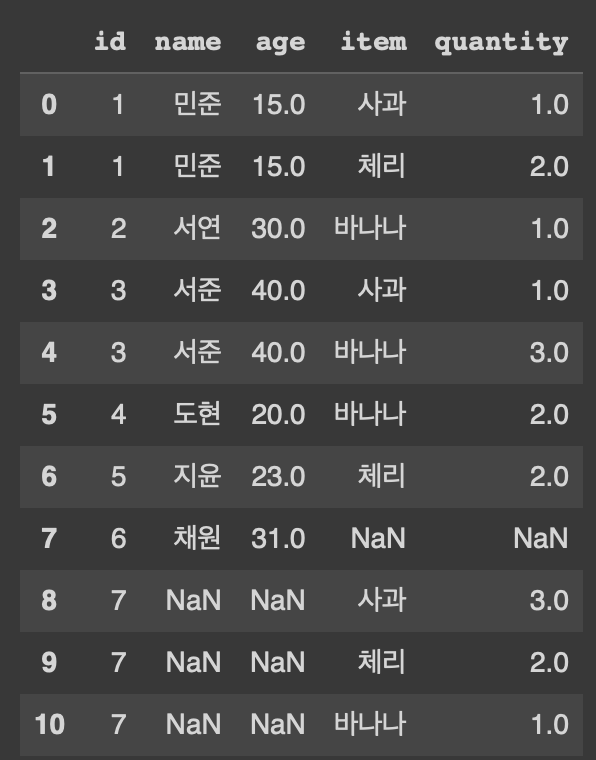
customer과 orders 데이터들 모두 추출되고, id값 같으면 연결되고 연결 안되는 부분은 null로
** 두 데이터 기준 컬럼명이 다를 경우 **
- pd.merge(데이터1, 데이터2, left_on: '데이터1의 기준컬럼명', right_on: '데이터2의 기준컬럼명', how='결합방법')
orders = orders.rename({'id':'customer_id'}, axis = 1)이러면 orders와 customer의 기준 컬럼명이 서로 다름
pd.merge(customer, orders, left_on = 'id', right_on = 'customer_id', how = 'inner')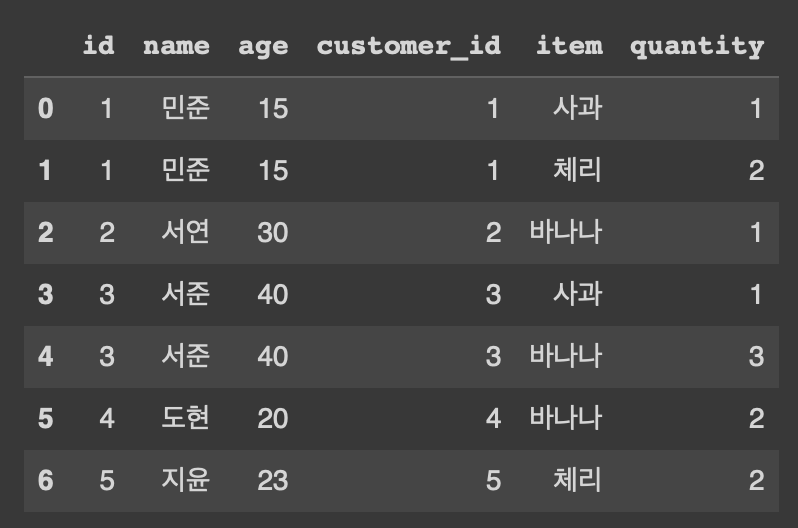
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| groupby (0) | 2024.06.11 |
|---|---|
| 데이터 분포와 통계량 (0) | 2024.06.11 |
| 데이터가공: apply, map, 문자열 다루기 (0) | 2024.06.11 |
| 날짜 데이터 (0) | 2024.06.04 |
| 데이터 타입 변환하기 (0) | 2024.05.30 |



