import pandas as pd
file_path = '/content/drive/MyDrive/data/temperatures.csv'
data = pd.read_csv(file_path)
df = data.copy()
#실습데이터를 준비해보아용~
df.info()But~ Date 컬럼의 데이터타입이 날짜형이 아닌 문자열임을 확인할 수 있당!

문자형을 날짜형으로 변경하기
- 날짜 계산을 위해 날짜형으로 변경
- pd.to_datetime(데이터변수['컬럼명'], format = '날짜형식'
날짜형식
- %Y: 4자리 연도
- %y: 2자리 연도
- %m: 월
- %d: 일
- %H: 시간
- %M: 분
- %S: 초
df['Date1'] = pd.to_datetime(df['Date'], format = '%Y-%m-%d')df의 Date 컬럼을 날짜형 (형식은 네자리연도-월-일)으로 변경하여 새로운 컬럼 Date1을 생성함
날짜형의 형식을 변경하기
- 데이터변수['컬럼명'].dt.strftime('날짜형식')
df['Date1'].dt.strftime('%Y-%m')4자리연도-월 형식으로 변경
df['Date1'].dt.strftime(%m-%d %H:%M)월-일 시각:분 형식으로 변경
시간데이터가 없기 때문에 00:00 값으로 세팅됨
dt 연산자
- year: 연도
- month: 월
- day: 일
- dayofweek: 요일을 숫자로 (0: 월요일 ~ 6:일요일)
- day_name(): 요일을 문자열로
df['year'] = df['Date1'].dt.year
#년도만 추출해서 새로운 컬럼으로
df['month'] = df['Date1'].dt.month
#월만 추출해서 새로운 컬럼으로
df['day'] = df['Date1'].dt.day
#일만 추출해서 새로운 컬럼으로
df['dayofweek'] = df['Date1'].dt.dayofweek
#요일을 숫자로 나타내서 새로운 컬럼으로
df['dayname'] = df['Date1'].dt.day_name()
#요일을 문자로 나타내서 새로운 컬럼으로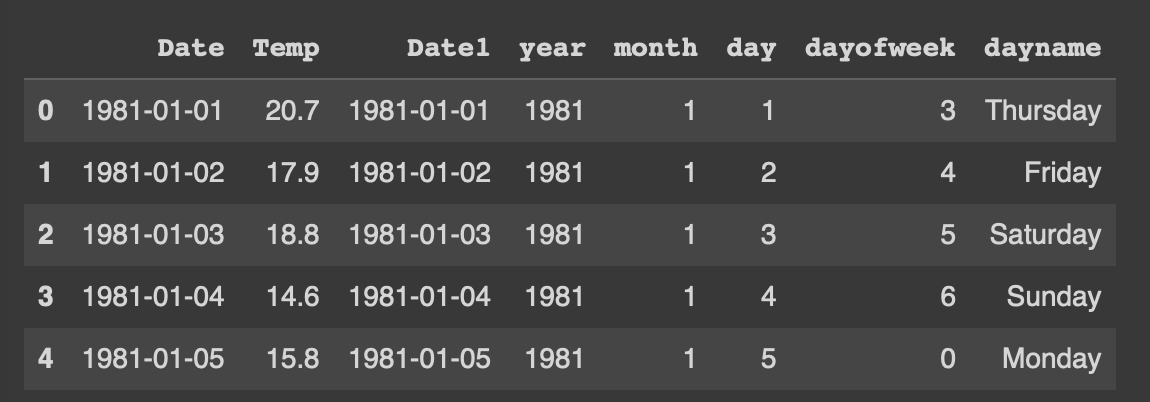
날짜 연산
- day 연산: pd.Timedelta(days=숫자)
- month 연산: pd.DateOffset(months=숫자)
- year 연산: pd.DateOffset(years=숫자)
df['plus day1'] = dt['Date1'] + pd.Timedelta(days=1)Date1에 하루를 더한 날짜데이터를 plus day1이라는 새로운 컬럼으로..
df['plus day7'] = df['Date1'] + pd.Timedelta(days=7)Date1에 일주일을 더한 날짜 데이터를 plus day7이라는 새로운 컬럼으로..
df['minus day7'] = df['Date1'] - pd.Timedelta(days=7)Date1에 일주일을 뺀 날짜 데이터를 minus day7이라는 새로운 컬럼으로..
from pandas.tseries.offsets import DateOffset
df['plus month1'] = df['Date1'] + DateOffset(months=1)Date1에 한달을 더한 데이터를 plus month1이라는 새로운 컬럼으로..
df['minus month3'] = df['Date1'] - DateOffset(months=3)Date1에 세 달을 뺀 데이터를 minus month3 이라는 새로운 컬럼으로..
df['plus year1'] = df['Date1'] + DateOffset(years=1)Date1에 1년을 더한 데이터를 plus year1 이라는 새로운 컬럼으로..
df['minus year3'] = df['Date1'] - DateOffset(years=3)Date1에 3년을 뺀 데이터를 minus year3라는 새로운 컬럼으로..
날짜 구간 데이터 생성하기
- pd.date_range(start='시작일자', end='종료일자', periods=기간수, freq='주기')
freq 주기
- D: 일별
- W: 주별
- M: 월별 (말일)
- MS: 월별 (시작일)
- A: 연도별 (말일)
- AS: 연도별 (시작일)
pd.date_range(start='2020-01-01', periods=30, freq='D')일별로 30기간, 즉 하루씩 30개 구간 데이터
2020-01-01부터 2020-01-30까지

pd.date_range(start='2020-01-01', end='2023-06-30', freq='M')2020-01-01부터 월 단위(월의 마지막 날)로 2023-06-30까지의 구간데이터 생성
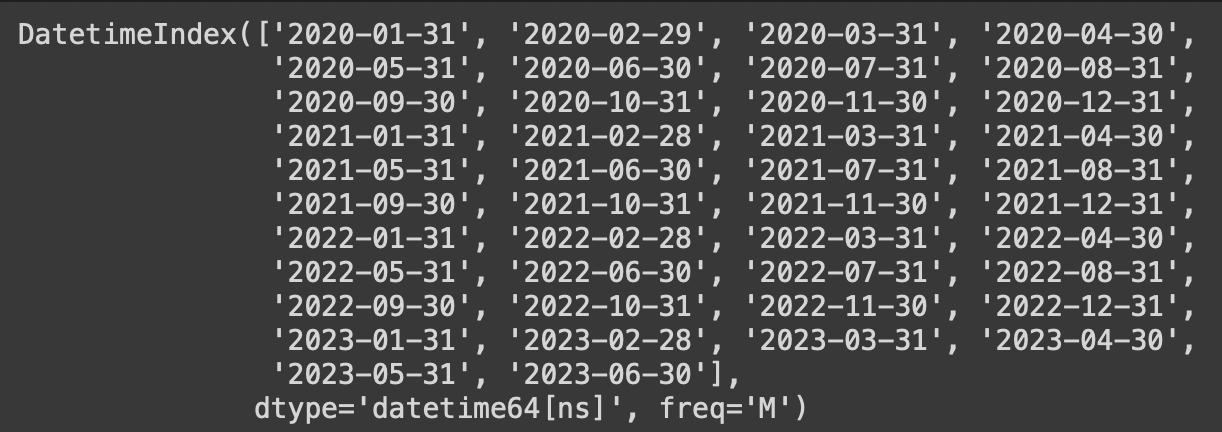
pd.date_range(start='2020-01-01',end='2023-06-30',freq='MS')2020-01-01부터 월 단위(월의 첫번째 날)로 2023-06-30까지의 구간 데이터 생성
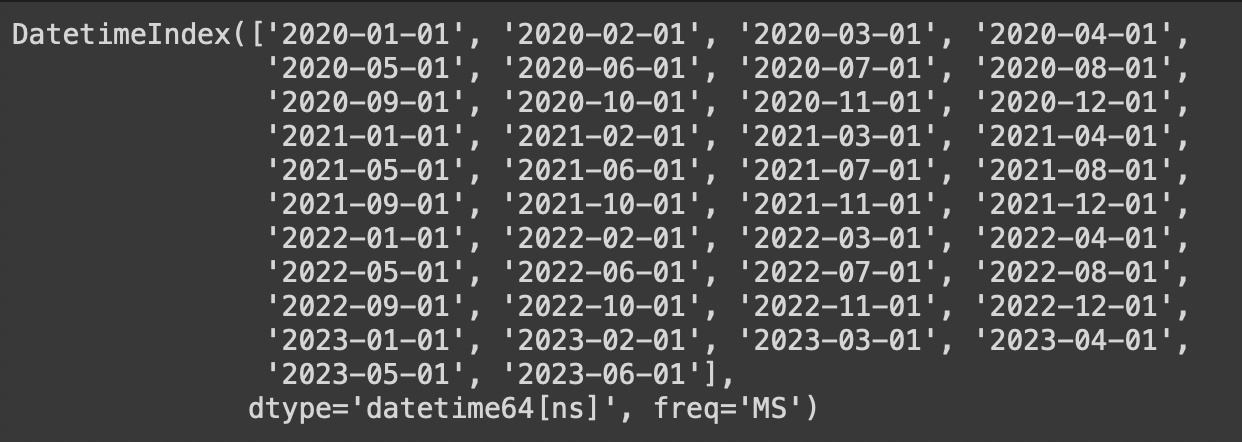
pd.date_range(start='2020-01-01',end='2023-06-30',freq='A')2020-01-01부터 2023-06-30까지 연 단위(매년 마지막 날)로 구간 데이터 생성
결과) 2020-12-31, 2021-12-31, 2022-12-31
pd.date_range(start='2020-01-01', end='2023-06-30', freq = 'AS')2020-01-01부터 2023-06-30까지 연 단위(매년 첫째 날)로 구간 데이터 생성
결과) 2020-01-01, 2021-01-01, 2022-01-01, 2023-01-01
rolling() 기간 이동 계산
- 데이터['컬럼명'].rolling(숫자).집계함수
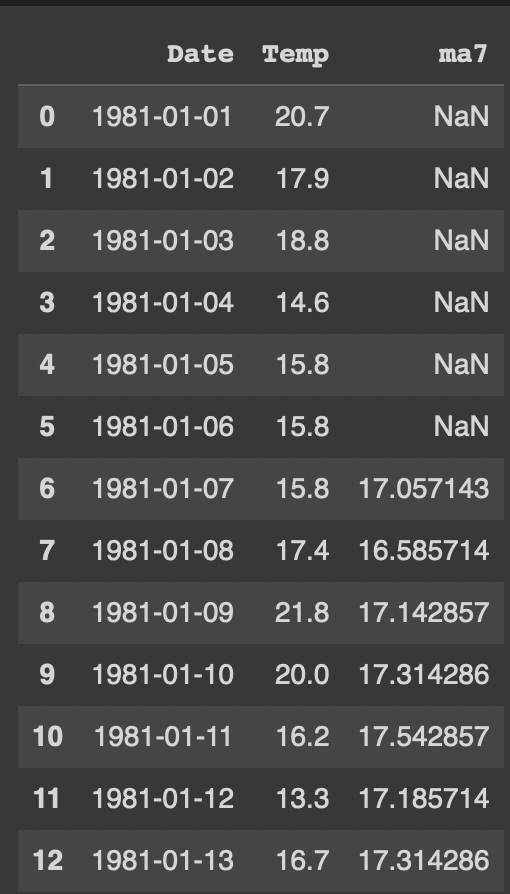
df1['ma7'] = df1['Temp'].rolling(7).mean()7일 이동평균 컬럼 ma7: 행을 아래로 이동하면서 해당 행 포함 직전 7행의 평균을 구함
해당 행 포함 직전 7행이 존재하는 7번째 행(인덱스=6)부터 값이 존재한다.
df1['Temp'].rolling(7).sum()해당 행 포함 직전 7개 행의 합
df1['Temp'].rolling(7).min()
df1['Temp'].rolling(7).max()
해당 행 포함 직전 7개 행들 중 최솟값, 최댓값
행 이동하기
- 데이터['컬럼명'].shift(이동할 행의 수)
df2['Temp shift1'] = df2['Temp'].shift(1)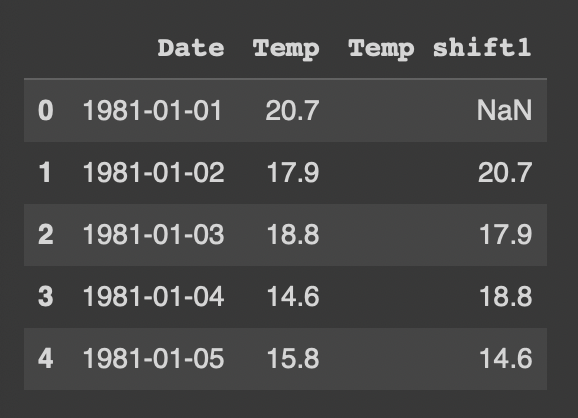
Temp 컬럼 데이터들이 행 하나씩 밀린 것을 확인할 수 있다.
df2['pct change'] = (df2['Temp shift1'] - df2['Temp']) / df2['Temp']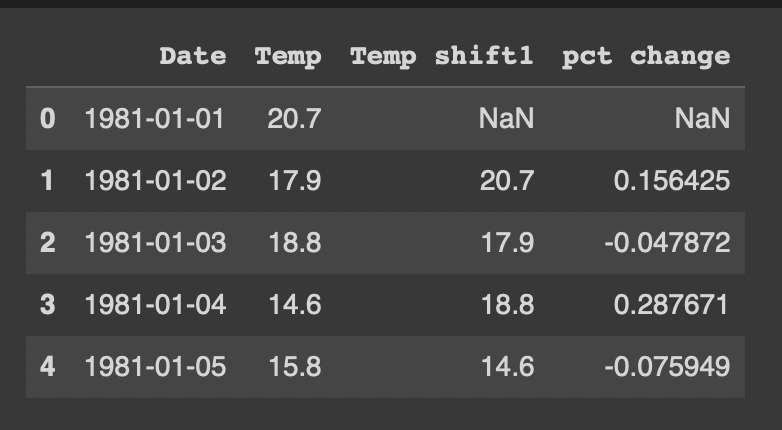
이를 통해 증감률을 쉽게 구할 수 있음
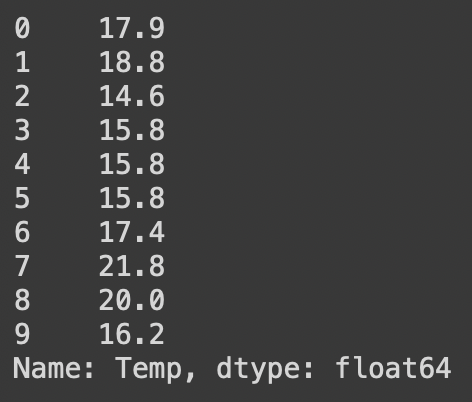
df2['Temp'].shift(-1).head(10)shift 숫가 값에 음수를 넣으면 행이 반대 방향으로 밀린다! (아래->위)
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 데이터 결합 (0) | 2024.06.11 |
|---|---|
| 데이터가공: apply, map, 문자열 다루기 (0) | 2024.06.11 |
| 데이터 타입 변환하기 (0) | 2024.05.30 |
| 결측값 처리하기 (0) | 2024.05.30 |
| 인덱스, 행, 그리고 열 (0) | 2024.05.30 |



