import pandas as pd
file_path = '/content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)
인덱스
- 인덱스란 데이터프레임 행들의 이름
df.head()
#데이터프레임 df를 먼저 확인해봅시당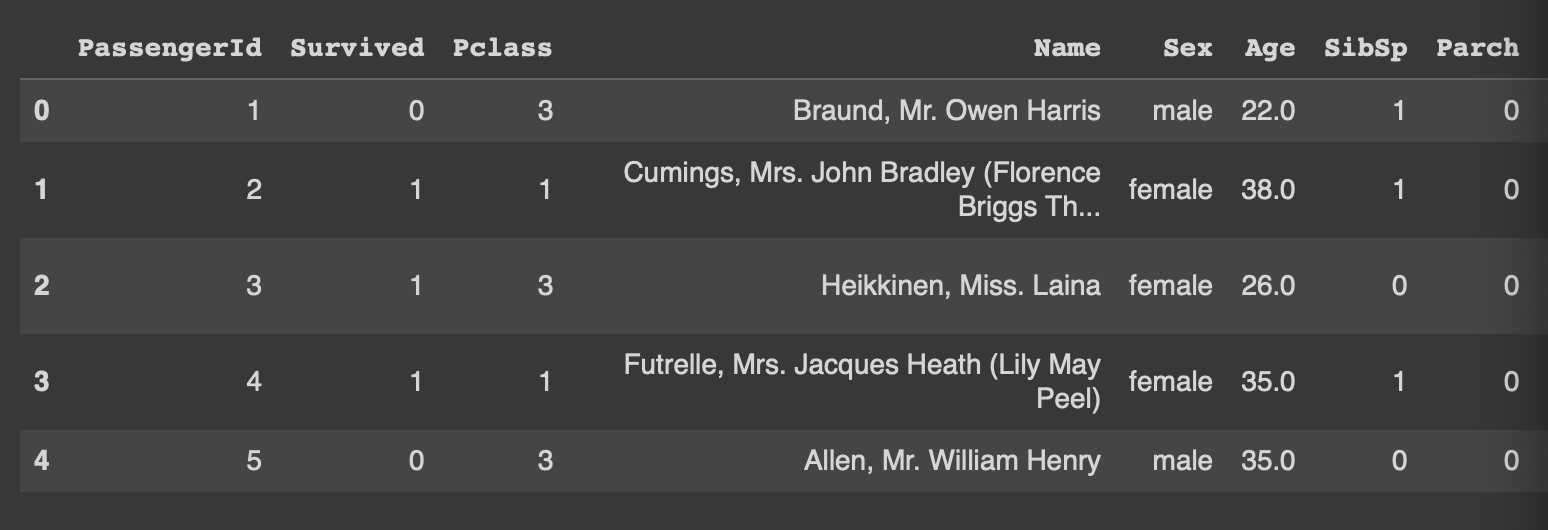
df에서 인덱스는 0,1,2,...
df.index
# df의 인덱스에 대한 정보를 확인해봐용
0에서 시작(start=0)해서 하나씩 증가(step=1)하며 890(strop=891)까지 있다는 뜻
: 총 891개의 행
인덱스 변경
- 인덱스 일부를 바꿀 때: 데이터명.rename({기존인덱스1: 바꿀 인덱스1, 기존인덱스2: 바꿀 인덱스2, ...})
- 인덱스 전체를 바꿀 때: 데이터명.index = 바꿀 인덱스 리스트
df1= df.copy()
df1.rename({0: 'row1', 1: 'row2'})df1에 df를 복사해서 넣고
데이터프레임명.rename()을 통해 기존인덱스 0을 'row1'로, 1을 'row2'로 변경
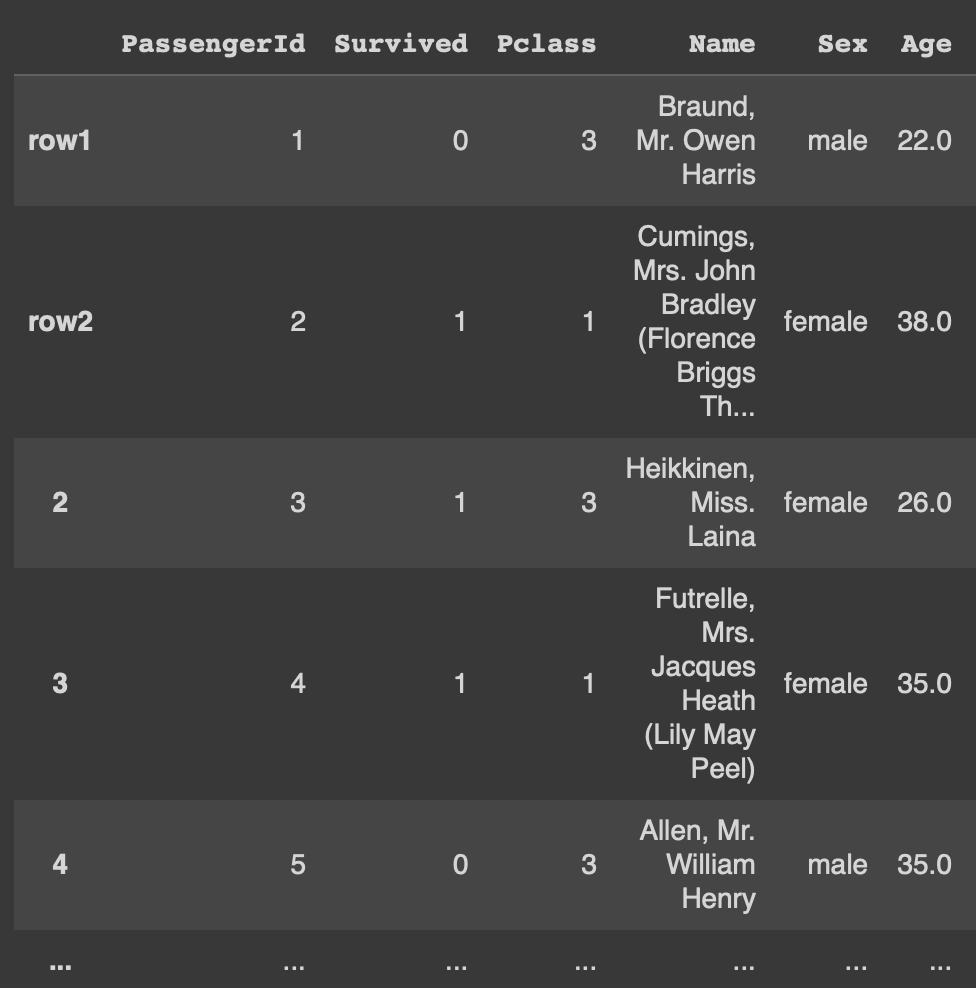
**하지만! rename을 통해 변경한 내용을 반영하려면 덧씌워야함!!**
이상태로 df1을 확인해보면 인덱스는 기존 인덱스에서 변경되지 않은 상태임
df1 = df1.rename({0:'row1', 1:'row2'})이런식으로 덮어씌워줘야 반영된다.
df1.index = [i+1 for i in range(len(df1))]
df1.head() #확인해보아요인덱스 전체를 바꾸고 싶을 때는 데이터프레임명.index = 바꿀 인덱스 리스트 를 넣어주면 됨
df1에 있는 행 개수 만큼 반복하며 인덱스가 0+1, 즉 1부터 df1길이까지 생김 (원래 0,1,2,3, ... => 이제 1,2,3,4,...)

열을 인덱스로 설정
- 특정 컬럼을 인덱스로 사용하고 싶을 때는 데이터명.set_index('컬럼명')
df1.set_index('PassengerId')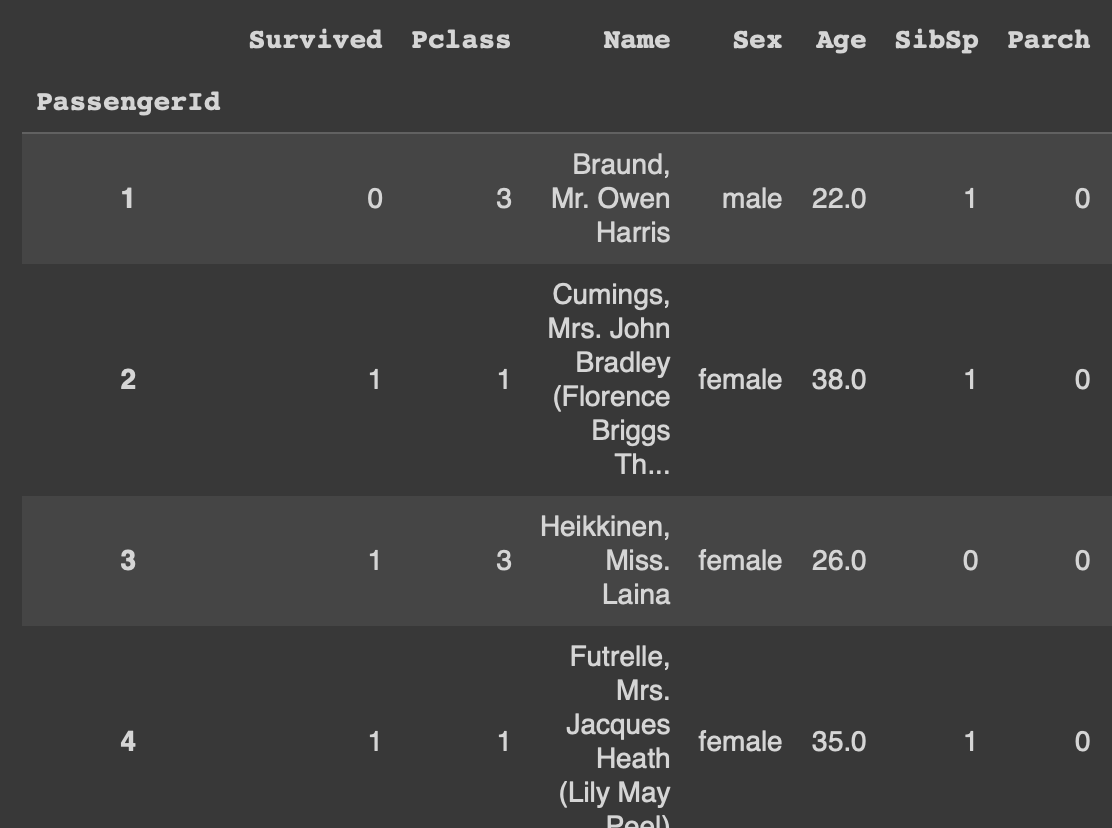
**하지만~ 이것도 마찬가지로 반영 안되기 때문에 ㄹㅇ로 데이터를 "변경"하려면 덮어 씌워줘야 해
df1 = df1.set_index('PassengerId')이렇게~
인덱스를 열로 변환
- 인덱스를 열로 변환하고 그 열을 남겨두려면: 데이터명.reset_index()
- 인덱스를 열로 변환하고 그 열을 삭제하려면: 데이터명.reset_index(drop = True)
위의 df1 상태에서 아래 코드를 실행하면..
df1.reset_index()
인덱스였던 PassengerId는 다시 열(컬럼)에 들어가고,
기본 위치인덱스인 0,1,2,... 가 나타난다.
df1.reset_index(drop = True) 였다면 PassengerId 컬럼이 삭제됨
df1 = df1.reset_index()마찬가지로 reset_index() 도 반영하려면 덮어씌워줘야 한다!
행 row
행의 추가, 제거
- 행의 추가: pd.concat([기존데이터명, 추가할데이터명])
- 행의 제거: 데이터명.drop(인덱스명,
axis = 0)
df1 = df.copy()
df2 = df.copy()
df3 = pd.concat([df1,df2])df1에 df2를 붙여서 새로운 데이터 df3을 생성함 (총 891*2개의 행)
인덱스는 0~890, 0~890 이렇게 됨(기존에 각 데이터에 있던 인덱스 그대로 유지)
df3 = df3.reset_index(drop=True)위 코드를 실행하면 0~1781의 인덱스가 생성됨
drop=True 옵션을 넣어주면 기존에 있던 0~890, 0~890 인덱스는 삭제된다.
df3.drop([i for i in range(891, len(df3))])drop()을 통해 행을 제거한다: 이 경우 891번 인덱스 행부터 끝까지 제거됨
drop()은 디폴트로 axis = 0 옵션이 적용되기 때문에 행을 삭제 할 경우 axis = 0을 명시하지 않아도 됨
axis=1은 열 제거할 때 이용
중복 행 제거
- 데이터명.drop_duplicates()
df3 = df3.drop_duplicates()중복되는 행이 제거됨: 위와 같이 반영하려면 덮어 씌워야 한다.
열 column
열의 추가, 제거
- 열의 추가: 데이터명['추가할 컬럼명'] = 추가할 값
- 열의 제거: 데이터명.drop('제거할 컬럼명', asix = 1)
df1 = df.copy()
df1['age_simplified'] = df1['Age'] // 10 * 10원본데이터를 복사해서 df1에 저장
age_simplified라는 새로운 컬럼을 생성,
그 값들은 원래 있던 Age 컬럼값을 10으로 나눈 몫에 10을 곱한 것
즉, 0,10,20,30, ... 의 값 중 하나: 10세 단위의 연령대

separatedNames = list(df1['Name'].str.split(','))문자열 컬럼에 .str.split('기준문자')를 쓰면 특정 문자(열)를 기준으로 자를 수 있다.
df1의 Name 컬럼에 해당하는 값들은 각각 컴마를 기준으로 분리되어 separatedNames 리스트에 담김
separatedNames는 리스트 안에 리스트원소들로 이루어짐
ex) [['Braund', 'Mr.Owen Harris'], ['Cumings', 'Mrs. John Bradley'], ... ]
df1['first_name'] = [i[0] for i in separatedNames]df1에 새로운 컬럼인 first_name을 생성,
그 값은 separatedNames 리스트에 있는 각 리스트원소의 첫번째 원소가 된다.

df1.drop('first_name', axis = 1)
df1.drop(['Cabin', 'age_simplified'], axis = 1)drop함수 쓸 때 열을 삭제하기 위해서는 axis = 1 옵션을 꼭 명시해야 한다.
여러개 열을 삭제하고 싶으면 리스트로 묶어주기
**하지만 위 코드의 경우 반영은 안됨, df1 = df1.drop()~ 이렇게 덧씌워줘야 레알루 반영됨.
반복학습~
열 이름 변경
- 원하는 열(들) 이름 바꾸기: 데이터명.rename({'기존열이름1': '바꿀열이름1', '기존열이름2': '바꿀열이름2', ...}, axis=1)
- 열 이름 전체 바꾸기: 데이터명.columns = 열이름리스트
df1 = df.copy()
df1 = df1.rename({'PassengerId': 'Id'}, axis = 1)
#반영하려면 덮어씌우기df1의 PassengerId 컬럼명이 Id로 변경됨
df1.columns = [i for i in range(16)]
#df1 컬럼개수 16개컬럼명이 전부 바뀜 0, 1, 2, ... 15로

'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 데이터 타입 변환하기 (0) | 2024.05.30 |
|---|---|
| 결측값 처리하기 (0) | 2024.05.30 |
| 조건에 맞는 데이터 추출하기! (0) | 2024.05.28 |
| 데이터(CSV, EXCEL, HTML) 불러오고 저장하기 (0) | 2024.05.28 |
| 외부 데이터 파일을 불러와 구글 코랩(colab)에서 이용하기 (0) | 2024.05.24 |


