- 같은 값을 한 그룹으로 묶어서 여러가지 연산 및 통계량 구하기
- 데이터.groupby('컬럼명').연산및통계함수()
from google.colab import drive
drive.mount('/content/drive')import pandas as pd
file_path = '/content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)실습 데이터 중비~
df.groupby('Pclass').count()
Pclass값을 기준으로 나눈 그룹 별 null이 아닌 행의 갯수
df.groupby('Pclass').nunique()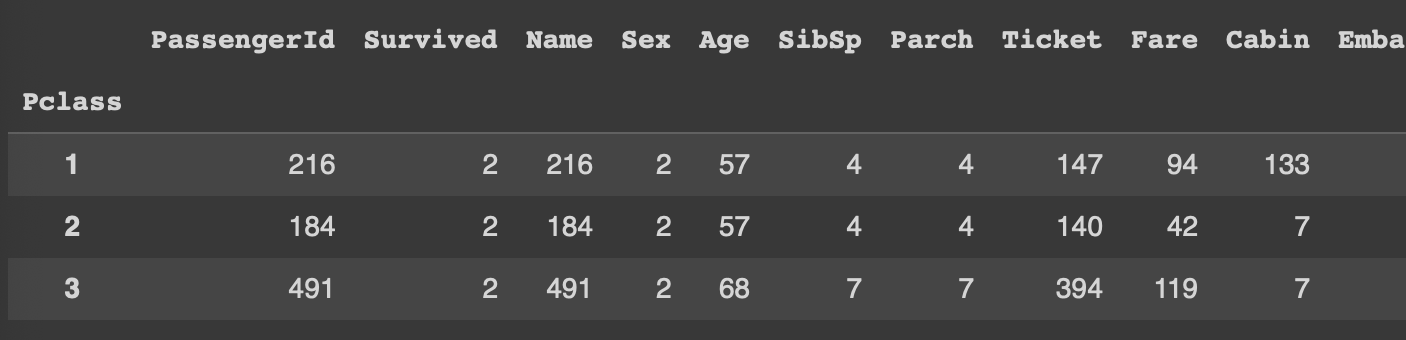
Pclass값을 기준으로 나눈 그룹 별 유니크한 행의 갯수
ex) Survived는 0또는 1로 이루어져 있기 때문에 유니크한 행의 갯수는 최대 두개
df.groupby('Pclass').sum(numeric_only = True)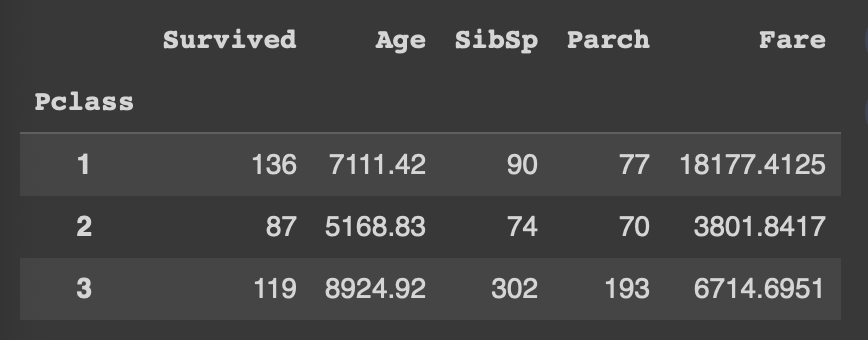
Pclass 값을 기준으로 나눈 그룹 별 각 숫자데이터컬럼의 합 계산
df.groupby('Pclass').mean(numeric_only = True)
# Pclass 그룹 별 숫자형 데이터 컬럼들의 평균
df.groupby('Pclass').min(numeric_only = True)
# Pclass 그룹 별 숫자형 데이터 컬럼들의 최솟값
df.groupby('Pclass').max(numeric_only = True)
# Pclass 그룹 별 숫자형 데이터 컬럼들의 최댓값
df.groupby('Pclass').std(numeric_only = True)
# Pclass 그룹 별 숫자형 데이터 컬럼들의 표준편차
df.groupby('Pclass').var(numeric_only = True)
# Pclass 그룹 별 숫자형 데이터 컬럼들의 분산그 외..
df.groupby('Pclass')[['Survived']].mean()

Pclass 그룹 별 Survived 컬럼의 평균값
df.groupby('Pclass')[['Survived', 'Age']].mean()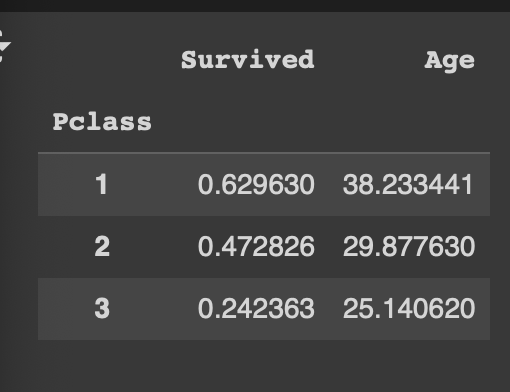
Pclass 그룹 별 Survived와 Age 컬럼의 평균값
두 컬럼 모두 데이터가 다 숫자형으로만 이루어져 있기 때문에 numeric_only = True 필요 없음
다중 그룹
df.groupby(['Sex','Pclass']).mean(numeric_only = True)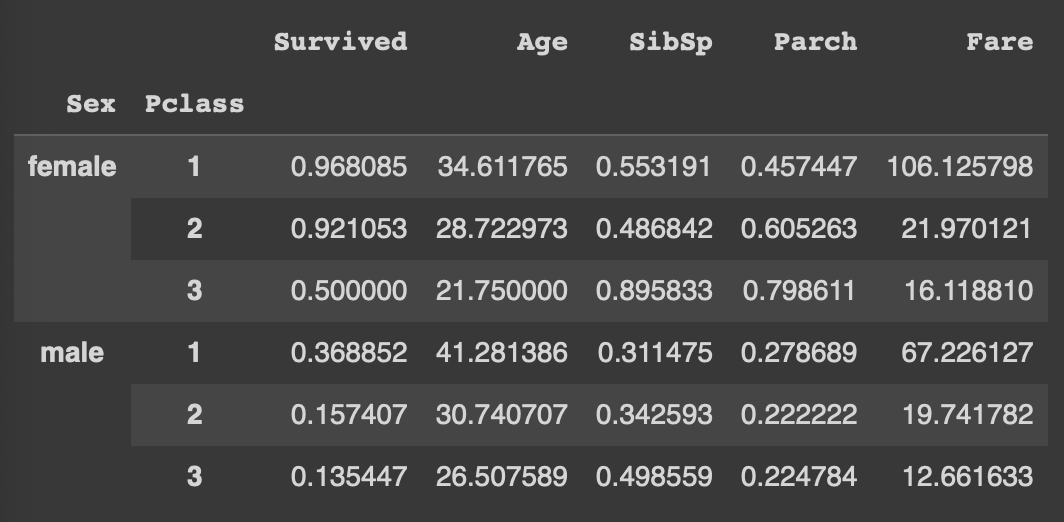
Sex와 Pclass 두 컬럼을 기준으로 그룹을 나눈 후(2*3개의 그룹),
숫자형 데이터들을 가지는 컬럼들의 평균값 계산
import numpy as np
df.groupby(['Sex','Pclass'])[['Survived','Age','SibSp','Parch','Fare']].aggregate([np.mean, np.min, np.max])*aggregate: 여러개의 통계값을 한번에 구할 때 사용
Sex와 Pclass 두 컬럼을 기준으로 그룹을 나눈 후 (2*3개의 그룹),
그룹 별 Survived, Age, SibSp, Parch, Fare 컬럼의 통계값(평균, 최솟값, 최댓값) 계산
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 피벗테이블 (0) | 2024.06.12 |
|---|---|
| crosstab (0) | 2024.06.11 |
| 데이터 분포와 통계량 (0) | 2024.06.11 |
| 데이터 결합 (0) | 2024.06.11 |
| 데이터가공: apply, map, 문자열 다루기 (0) | 2024.06.11 |



