- 데이터를 행과 열로 그룹화하여 (=crosstab) 요약통계를 계산!
- pd.pivot_table(데이터명, index = '행 기준', columns = '열 기준', values='값에 적용될 컬럼', aggfunc = '집계함수')
from google.colab import drive
drive.mount('/content/drive')import pandas as pd
file_path = '/content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)
실습데이터 준비
단일인덱스, 단일 컬럼, 단일 값 피벗테이블
pd.pivot_table(df, index='Sex', columns = 'Pclass', values='Survived', aggfunc = 'mean')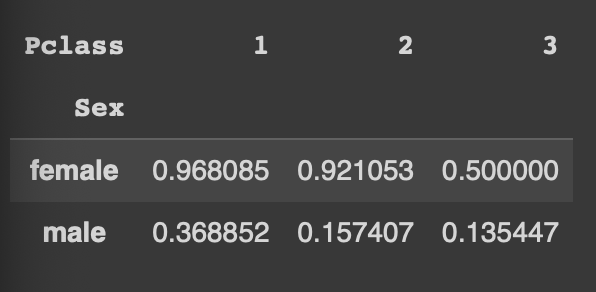
행 기준은 Sex, 열 기준은 Pclass, 각 값에는 그룹 별 Survived의 평균!
여자일수록, Pclass가 높을수록(1에 가까움) 생존 확률이 올라갔음을 유추할 수 있다.
pd.pivot_table(df, index = 'Sex', columns = 'SibSp', values = 'Survived', aggfunc = 'mean')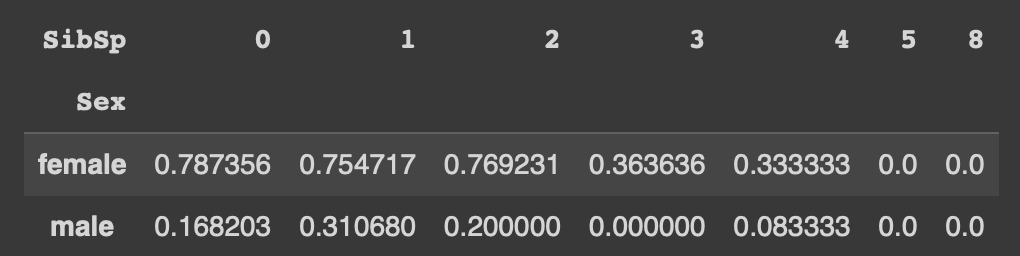
행 기준은 Sex, 열 기준은 SibSp(동반 가족의 수), 각 값에는 그룹 별 Survived의 평균!
동반 가족이 없을수록 생존확률이 높았다고 유추할 수 있다.
pd.pivot_table(df, index='Sex', columns='Survived', values='Age', aggfunc='mean', margins=True)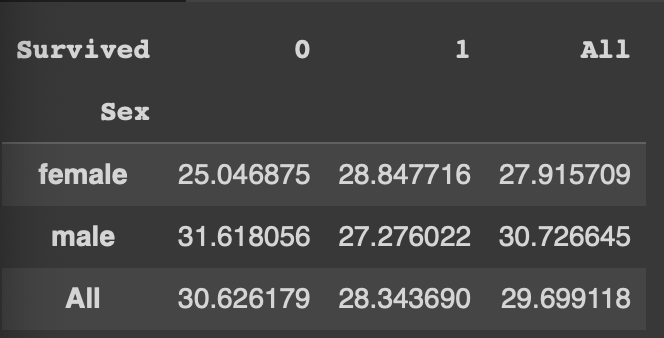
margins=True 옵션을 통해 각 행(열)의 전체 평균도 구할 수 있다.
pd.pivot_table(df, index='Sex', columns='Survived', values='Age', aggfunc=['max','min','mean'])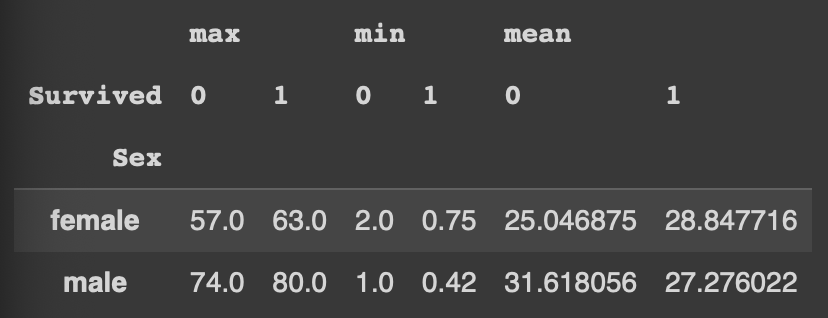
aggfunc에 리스트로 여러개의 집계함수를 넣으면 여러개의 연산을 한번에 할 수있다.
다중 인덱스, 다중 컬럼, 다중 값 피벗테이블
pd.pivot_table(df, index=['Sex','Pclass'], columns='Survived', values='Age', aggfunc='mean')
다중인덱스: 행 기준이 Sex와 Pclass
열 기준은 Survived, 값에는 그룹별 나이 평균
pd.pivot_table(df, index='Survived', columns=['Sex','Pclass'], values='Age', aggfunc='mean')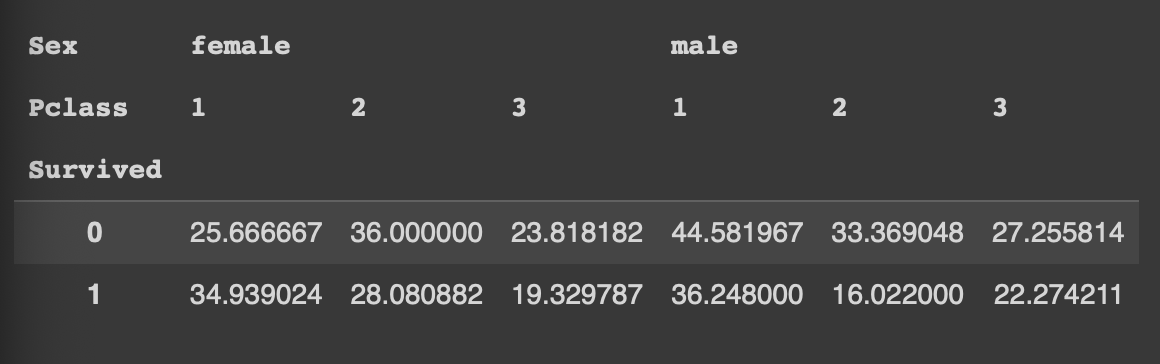
다중컬럼: 열 기준은 Sex와 Pclass
행 기준은 Survived, 값에는 그룹별 나이 평균
pd.pivot_table(df, index=['Sex','Pclass'], columns=['Survived','Embarked'], values='Age', aggfunc='mean')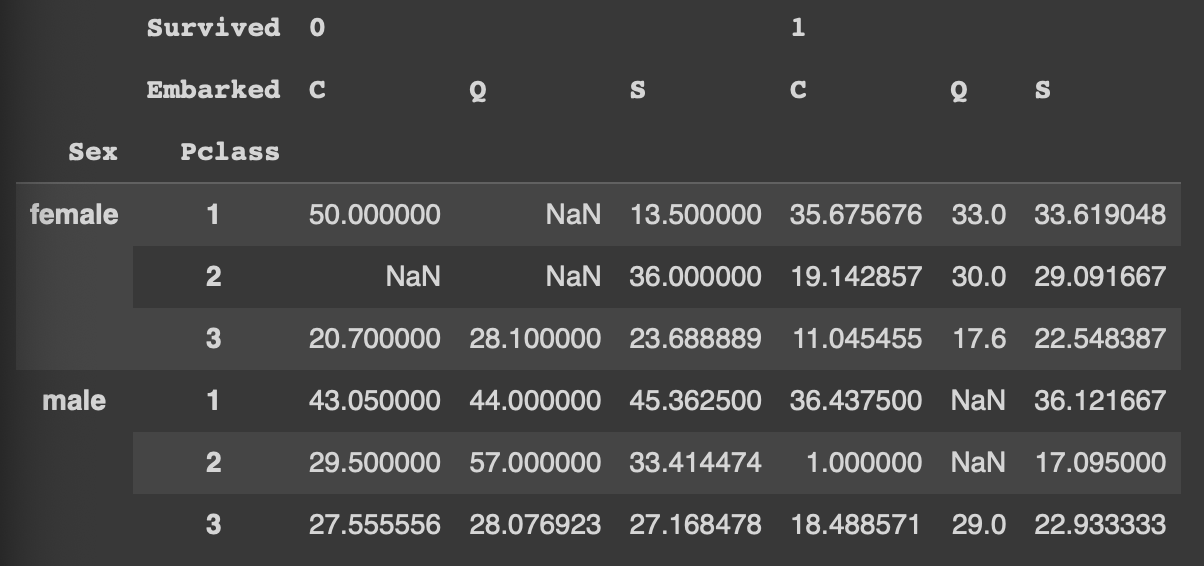
다중인덱스: 행 기준은 Sex와 Pclass
다중컬럼: 열 기준은 Survived와 Embarked
값에는 그룹별 나이 평균
pd.pivot_table(df, index=['Sex','Pclass'], columns=['Survived','Embarked'], values=['Age','Fare'], aggfunc='mean')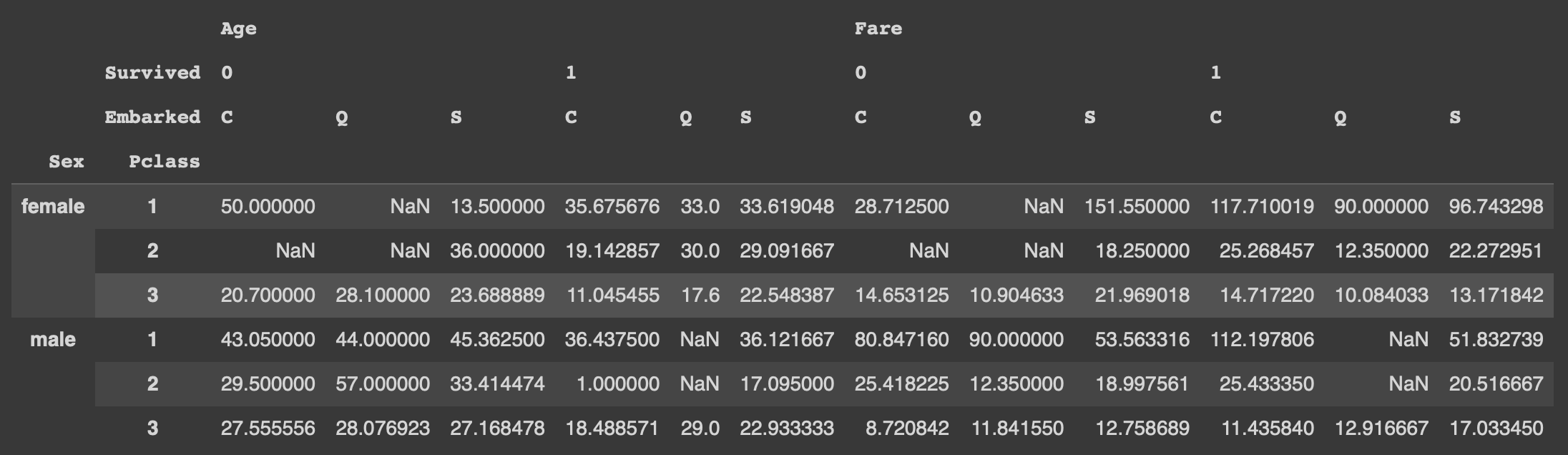
다중인덱스: 행 기준은 Sex와 Pclass
다중컬럼: 열 기준은 Survived와 Embarked
다중값: 값은 age 평균, 그리고 Fare 평균
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 데이터 구조 변경: stack, unstack, melt (0) | 2024.06.12 |
|---|---|
| crosstab (0) | 2024.06.11 |
| groupby (0) | 2024.06.11 |
| 데이터 분포와 통계량 (0) | 2024.06.11 |
| 데이터 결합 (0) | 2024.06.11 |



