stack, unstack
- stack: 컬럼을 인덱스로
- unstack: 인덱스를 컬럼으로 (stack의 반대)
from google.colab import drive
drive.mount('/content/drive')import pandas as pd
file_path = '/content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)실습데이터 중비
pivot = pd.pivot_table(df, index=['Sex','Pclass'], values = ['Survived','Fare'], aggfunc = ['mean','median','sum'])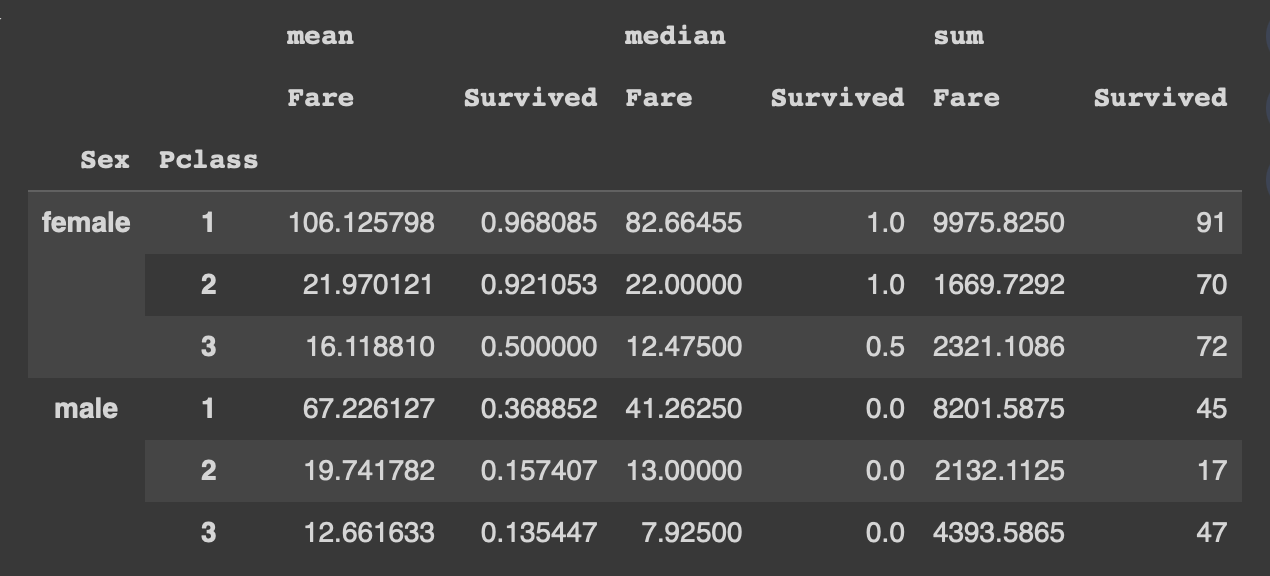
pivot.stack(0)첫번째 레벨(0)의 컬럼을 인덱스로 바꿈
(위에서부터 레벨 0 )

pivot.stack(1)두번째 레벨의 컬럼(1)을 인덱스로 바꿈
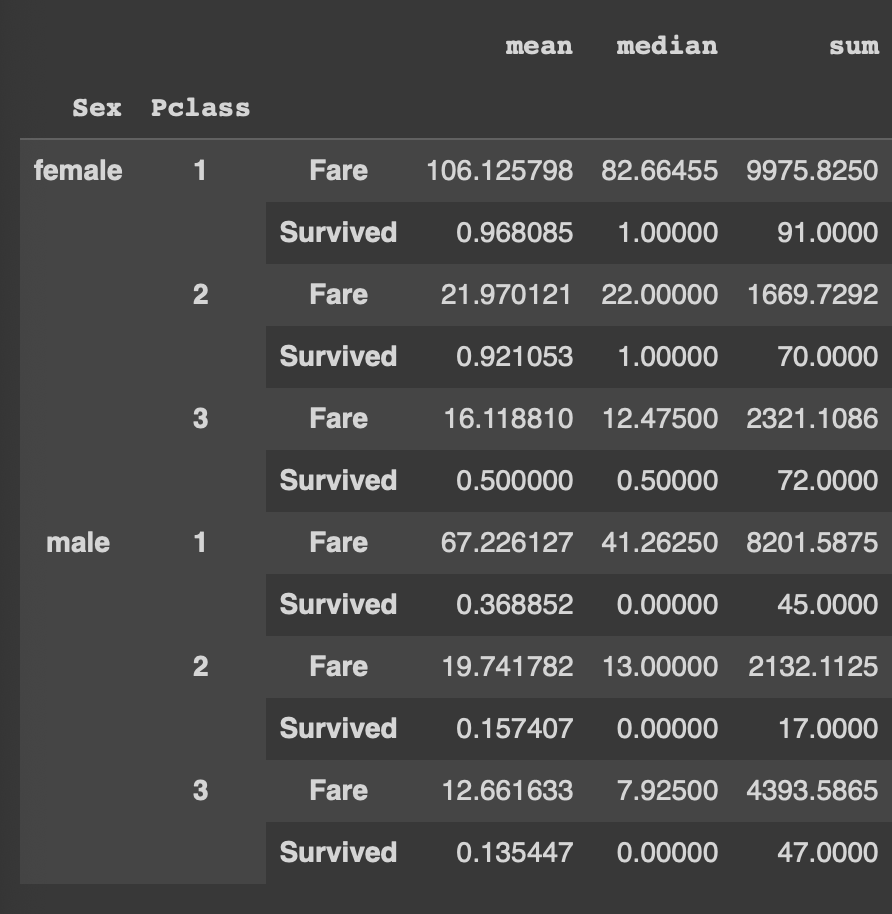
pivot.unstack(0)첫번째 레벨의 인덱스를 컬럼으로 올림
(왼쪽에서부터 레벨 0)

pivot.unstack(1)두번째 레벨의 인덱스를 컬럼으로 올림

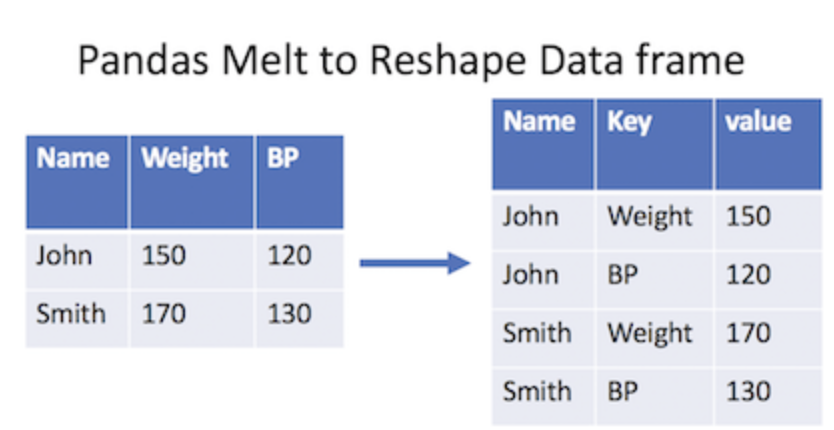
melt
- wide data frame을 long data frame으로!
- pd.melt(데이터명, id_vars = ['기준컬럼'])
data = pd.DataFrame({'name':['a','b','c']
, 'order_count':[3,4,10]
, 'amount':[10000,25000,300000]})실습을 위한 데이터프레임 생성

pd.melt(data, id_vars=['name'])
data 데이터프레임을 name컬럼을 기준으로 long~하게 바꾸기.
***
melt는 데이터프레임을 인덱스 제외 3개의 컬럼으로 바꾼다 (기준컬럼명, variable, value)
기준 컬럼에는 id_vars에 지정한 컬럼이 들어가고,
variable에는 기존 데이터프레임에 있던 컬럼들이(기준컬럼제외),
value는 각 컬럼의 값이 들어간다.
***
정리하면, melt를 하게되면
(기준이되는 컬럼의 서로다른 값 개수 * 기존데이터프레임에서 기준컬럼 제외 컬럼 개수) 개의 행이 생성된다.
하 나 글로 정리하는거 진짜 못한다!!!!!
쓰다보면 늘겠지..ㅜㅜ
pd.melt(data, id_vars=['name'], var_name = 'type', value_name = 'val')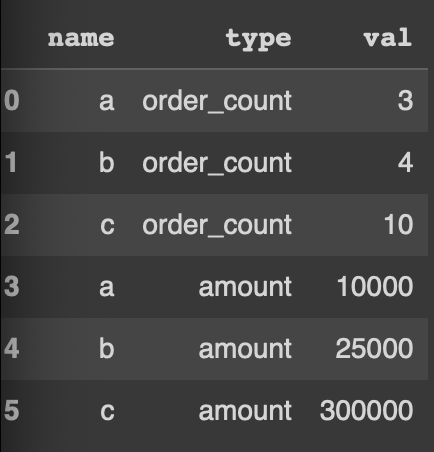
variable 컬럼명과 value 컬럼명도 지정해줄 수 있다.
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 피벗테이블 (0) | 2024.06.12 |
|---|---|
| crosstab (0) | 2024.06.11 |
| groupby (0) | 2024.06.11 |
| 데이터 분포와 통계량 (0) | 2024.06.11 |
| 데이터 결합 (0) | 2024.06.11 |



