- 범주형 데이터 비교분석 시 유용
- pd.crosstab(index = '행 기준', columns = '열 기준', margins=True(합 표시)/False, normalize='합기준')
- 행과 열 기준을 지정하여 교차표를 만들고, 각 기준에 해당하는 데이터의 갯수를 센다 (+비율까지)
from google.colab import drive
drive.mount('/content/drive')import pandas as pd
file_path = '/content/drive/MyDrive/data/titanic_train.csv'
df = pd.read_csv(file_path)실습데이터 준비준비
범주별 갯수 구하기
- pd.crosstab('행 기준이 될 컬럼', '열 기준이 될 컬럼')
pd.crosstab(df['Sex'], df['Survived'])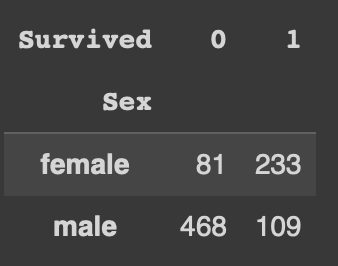
행 기준은 Sex, 열 기준은 Survived
성별이 여성이고 살아남지 못한 행은 81개, 성별이 여성이고 살아남은 행은 233개 ,... 등
범주별 비율 구하기
- normalize = 'all' : 전체 합을 1로 계산 (100%)
- normalize = 'index' : 각 행의 합을 1로 계산(100%)
- normalize = 'columns' : 각 열의 합을 1로 계산 (100%)
pd.crosstab(df['Sex'], df['Survived'], normalize = 'all')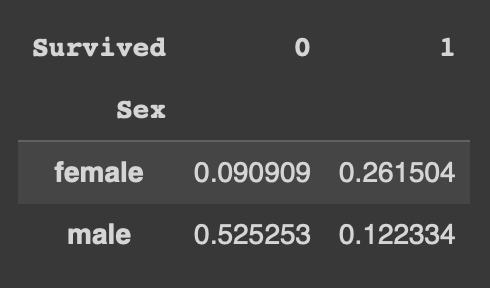
pd.crosstab(df['Sex'],df['Survived'],normalize = 'index')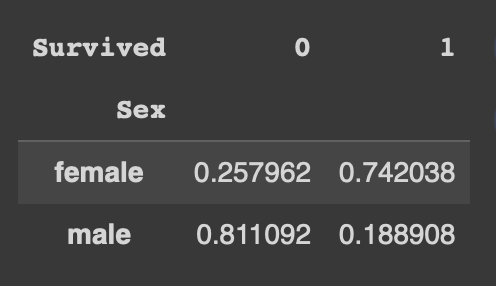
pd.crosstab(df['Sex'],df['Survived'],normalize='columns')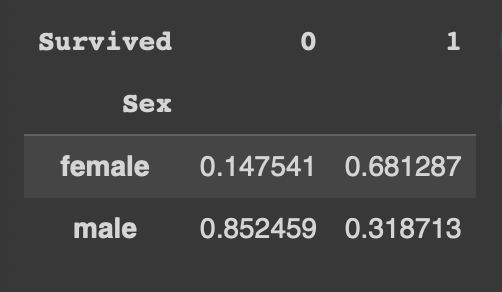
pd.crosstab(df['Sex'], df['Survived'], normalize = 'all', margins=True)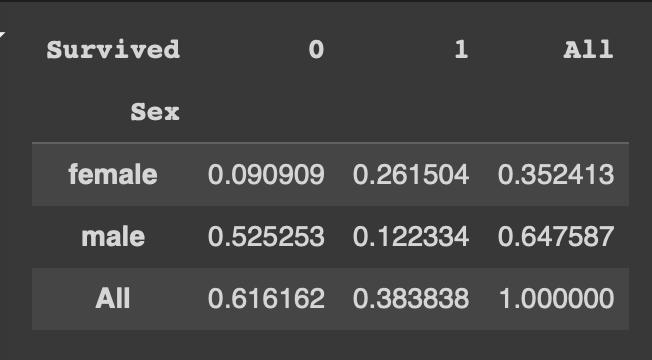
normalize= 'all'에 margins=True 옵션 추가 시 각 행과 열의 합 비율을 구할 수 있다.
pd.crosstab(df['Sex'],df['Survived'],normalize='index',margins=True)
normalize='index'에 margins=True 옵션 추가 시 각 열의 합 비율을 구할 수 있다.
* 각 행의 비율의 합은 100%
pd.crosstab(df['Sex'],df['Survived'],normalize='columns',margins=True)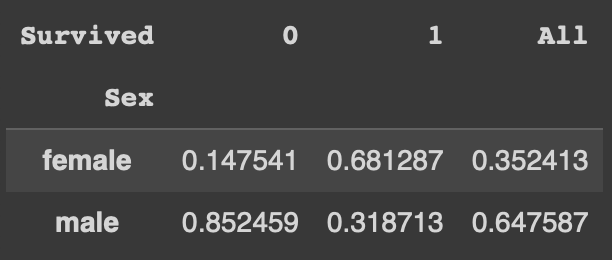
normalize='columns'에 margins=True 옵션 추가 시 각 행의 합 비율을 구할 수 있다.
* 각 열의 비율의 합은 100%
다중 인덱스, 다중 컬럼의 범주표
pd.crosstab(index=[df['Sex'],df['Pclass']], columns=df['Survived'])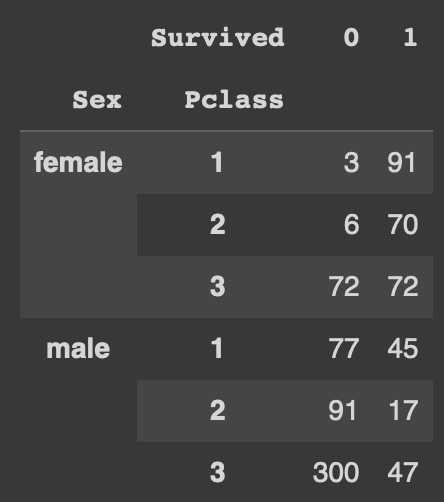
행 기준은 sex(값 두 개로 이루어짐), Pclass(값 세 개로 이루어짐)=> (2*3개의 행이 나옴)
열 기준은 Survived
pd.crosstab(index=[df['Sex'],df['Pclass']], columns=df['Survived'], normalize='all')위의 표에서 전체를 1로 하여 갯수가 아닌 비율로 표현
pd.crosstab(index=[df['Sex'],df['Pclass']], columns=[df['Survived'],df['Embarked']])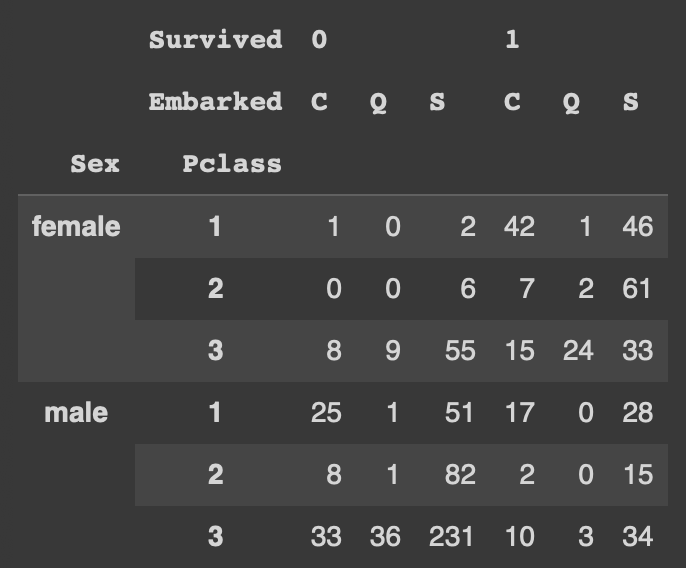
행 기준은 sex, pclass => 총 2*3개의 행
열 기준은 survived, embarked => 총 2*3개의 열
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 데이터 구조 변경: stack, unstack, melt (0) | 2024.06.12 |
|---|---|
| 피벗테이블 (0) | 2024.06.12 |
| groupby (0) | 2024.06.11 |
| 데이터 분포와 통계량 (0) | 2024.06.11 |
| 데이터 결합 (0) | 2024.06.11 |



