- 판다스(Pandas): 행과 열로 이루어진 대용량 데이터를 쉽게 처리하도록 지원하는 파이썬 라이브러리
- 데이터 분석에서 변수가 1개일 경우 => 시리즈, 변수가 2개 이상일 경우 => 데이터 프레임 사용
[Pandas 패키지의 추가]
import pandas as pd
#pandas 패키지를 불러와서 pd라는 이름으로 사용
1. 시리즈(Series): 1차원 배열 형태 구조, 파이썬 딕셔너리와 유사
2. 데이터 프레임(Data Frame): 2차원 테이블 형태 구조, 여러 개의 열(컬럼)과 행(로우)를 가지고, 각 열은 서로 다른 자료형 가능

출처)https://velog.io/@nata0919/Serise와-DataFrame-그림으로-정리하기
[시리즈(Series)]
1. 시리즈 객체 생성
sr1 = pd.Series([10,30,20,40,60])
#리스트를 시리즈 객체로 생성
print(sr1)
print()
print(sr1.values)
#시리즈 sr1의 값 출력
print(sr1.index)
#시리즈 sr1의 인덱스 출력 (처음값, 마지막 값, 증가폭)
print(sr1[2])
#시리즈 sr1의 인덱스 2에 해당하는 값 출력
2. 시리즈 객체의 인덱스 설정
: 0부터 시작하는 기본 숫자 인덱스와 함게 문자열 인덱스를 추가로 설정할 수 있음
sr1 = pd.Series([10,30,20,40,60], index=['a','b','c','d','e'])
#추가로 문자열 인덱스 설정
print(sr1[1])
#숫자 인덱스 사용
print(sr1['b'])
#문자열 인덱스 사용
3. 원소 선택
: 인덱스를 사용하여 시리즈의 원소를 하나만/한꺼번에 여러개 선택
sr1 = pd.Series([10,30,20,40,60], index=['a','b','c','d','e'])
print(sr1[[1,2]])
# 시리즈 sr1[1], sr1[2]의 값을 새로운 시리즈로 출력 (숫자 인덱스 사용)
print(sr1[1],sr1[2])
# 시리즈 sr1[1], sr1[2]의 값을 출력
print()
print(sr1[['a','c']])
# 시리즈 sr1['a'], sr1['c']의 값을 새로운 시리즈로 출력 (문자열 인덱스 사용)
print(sr1['a'],sr1['c'])
# 시리즈 sr1['a'], sr1['c']의 값을 출력
: 인덱스의 범위를 이용하여 원소 선택
*정수형 인덱스는 범위의 끝이 포함되지 않지만 문자열형 인덱스는 범위의 끝도 포함됨!!*
sr1 = pd.Series([10,30,20,40,60], index=['a','b','c','d','e'])
print(sr1[1:4])
# sr1[1]부터 sr1[3]까지 새로운 시리즈로 출력
print()
print(sr1['b':'e'])
# sr1['b']부터 sr1['e']까지 새로운 시리즈로 출력
[데이터프레임(Data Frame)]
1. 데이터프레임 객체 생성
: 2차원 리스트나 딕셔너리를 사용해서 데이터프레임으로 생성
df1 = pd.DataFrame([[10,20,30],[40,50,60]])
# 2행 3열을 갖는 2차원 구조
print(df1)
print()
dic1 = {'fruit' : ['apple', 'pear', 'tangerine', 'orange', 'banana'],
'price' : [100,200,150,50,200],
'quantity' : [10,25,30,20,15]}
df1 = pd.DataFrame(dic1)
# 딕셔너리 dic1을 데이터프레임으로 생성
print(df1)
2. 데이터프레임 객체의 인덱스(행) / 열 이름 정하기
: 기본 숫자 인덱스와 함께 추가로 문자열 인덱스도 설정 가능 / columns 키워드 이용하여 데이터프레임의 열 이름도 설정 가능
dic1 = {'fruit' : ['apple', 'pear', 'tangerine', 'orange', 'banana'],
'price' : [100,200,150,50,200],
'quantity' : [10,25,30,20,15]}
df1 = pd.DataFrame(dic1, index = ['a','b','c','d','e'])
#문자열 인덱스 추가 설정
print(df1)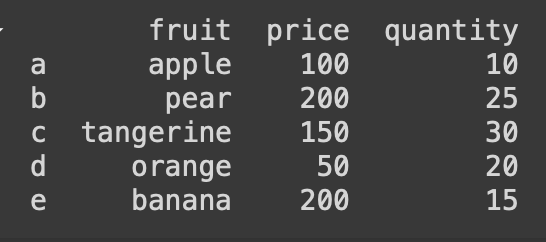
+ 생성된 데이터프레임의 인덱스/컬럼명 변경 시 rename() 메소드 이용
**inplace=True 옵션이 생략될 경우, 새로운 객체를 생성해서 반환한다**
df1.rename(columns = {'fruit' : '과일', 'price' : '가격', 'quantity' : '수량'}, inplace=True)
df1.rename(index = {'a' : '01', 'b' : '02', 'c': '03', 'd' : '04', 'e' : '05'}, inplace=True)
print(df1)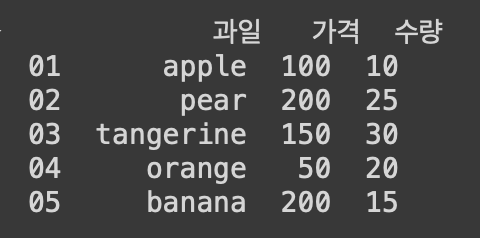
[데이터프레임(Data Frame) : 외부 데이터 이용하기]
**구글 드라이브에 있는 데이터 파일 불러오기**
2024.05.24 - [빅데이터분석기사_실기] - 외부 데이터 파일을 불러와 구글 코랩(colab)에서 이용하기
외부 데이터 파일을 불러와 구글 코랩(colab)에서 이용하기
1. 데이터 파일 업로드: 구글 드라이브 (Google Drive)의 Colab Notebooks 폴더 안에 데이터 파일(csv, xlsx)을 업로드 2. 코랩 Colab에서 다음 코드를 입력하고 실행from google.colab import drivedrive.mount('/content/drive
unikohoho.tistory.com
1. 데이터프레임 생성
: 구글 드라이브의 df_sample.csv 파일을 불러와서 데이터프레임 객체 df1으로 생성
df1 = pd.read_csv('/content/drive/MyDrive/Colab Notebooks/df_sample.csv')
#read_csv() 메소드 사용
df1
#print() 함수를 사용하지 않고, 변수(객체)명만 실행시켜도 변수(객체) 값을 출력
2. 데이터셋의 일부분만 보기
: 데이터셋의 앞부분을 보기 위해서는 head(), 마지막 부분을 보기 위해서는 tail() 메소드를 사용
df1.head(5)
#데이터프레임 df1의 앞부분에 있는 5개의 행 확인
3. 데이터 요약 정보 확인
df1.shape
: 데이터프레임의 shape 속성은 행과 열의 개수를 튜플 형태로 나타냄 => (행, 열)
df1.info()
: 데이터프레임의 info() 메소드는 데이터프레임에 관한 기본 정보를 화면에 출력
* 10 non-null : 해당 열(column)은 10개의 값(non-null)을 가짐을 뜻함
* dtype은 데이터 타입, object는 파이썬에서 string(문자열)과 같은 데이터 타입임
4. 데이터프레임의 기술 통계 정보 확인
: describe() 메소드 사용, 주요 기술 통계 정보를 요약해서 출력함
*기본적으로는 숫자 데이터를 갖는 열에만 적용되지만, include='all' 옵션을 추가하면 문자열 열에도 적용할 수 있음
df1.describe(include='all')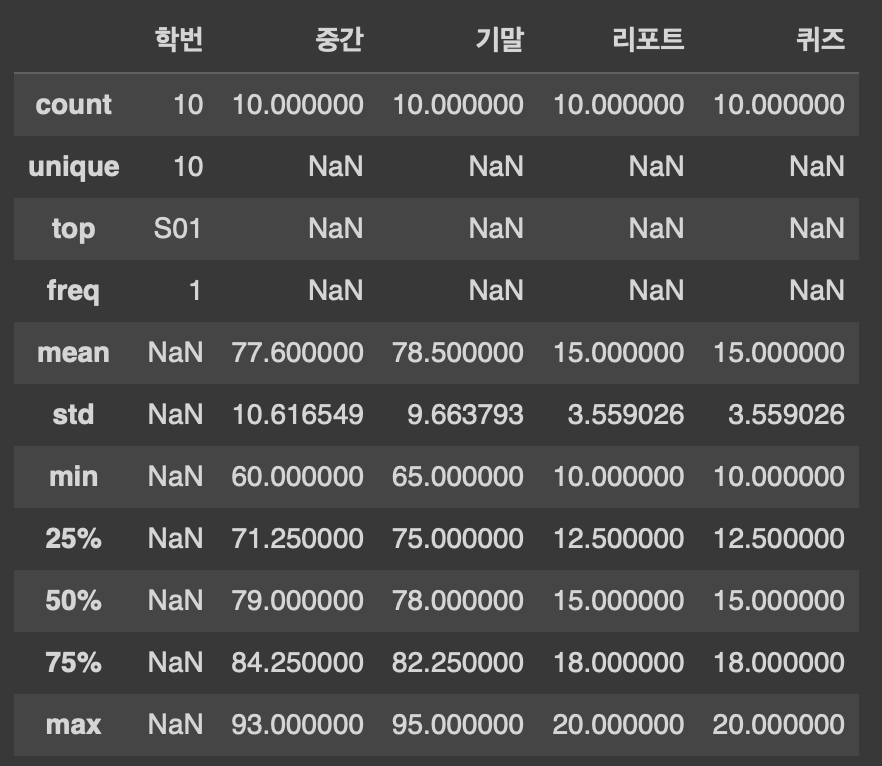
- count : 각 열에 있는 NaN(값이 없음을 뜻함)이 아닌 값의 개수
- unique : 중복 값을 제외한 고유한 값의 개수 *문자열 열에만 추가됨
- top : 가장 많이 나타나는 데이터 값 (최빈값) *문자열 열에만 추가됨
- freq : 가장 많이 나타나는 데이터 값 빈도 (빈도수) *문자열 열에만 추가됨
- mean : 평균, std : 표준편차, min : 최소값, max : 최대값 *숫자형 열에만 적용됨
- 25%, 50%, 75% : 전체 데이터의 1/4(Q1), 1/2(Q2, 중간값), 3/4(Q3) 지점의 데이터 값 *숫자형 열에만 적용됨
5. 통계 함수 적용하기
: 각 열(column)별 평균, 최대값, 최소값, 중간값, 표준편차 및 두 열 사이의 상관계수를 구할 수 있음
1. 컬럼의 평균값 : mean() 메소드
- 데이터프레임이름["열이름"].mean() 형식
- 열이름 생략 시 해당 데이터프레임의 모든 열 각각의 평균을 보여줌
print(df1['중간'].mean())
#데이터프레임 df1의 '중간'열의 평균 값 출력
print(df1[['중간','기말']].mean())
#df1의 '중간'과 '기말'열의 평균값을 새로운 시리즈(인덱스=각 열의 이름, 값=각 열의 평균 값)로 출력
2. 열의 최소값, 최대값, 중간값 : min(), max(), median() 메소드
- 데이터프레임이름['열이름'].메소드이름() 형식
- 열 이름 생략 시 전체 열 각각에 대해 적용
print(df1['학번'].min())
#df1의 '학번'열의 최소값 출력 **문자열형 열에도 적용됨**
print(df1[['중간','기말']].max())
#df1의 '중간'과 '기말'열의 최대값을 새로운 시리즈(인덱스=각 열의 이름, 값=각 열의 최대값)로 출력
print(df1['중간'].median())
#df1의 '중간' 열의 중간값을 출력 **숫자형 열에만 적용할 수 있음**
3. 열의 표준편차와 분산 : std(), var() 메소드
- 표준편차: std()
- 분산: var()
#표준편차
print(df1[['중간','기말']].std())
#df1의 '중간'과 '기말'열의 표준편차 값을 새로운 시리즈(인덱스=각 열의 이름, 값=각 열의 표준편차 값)로 출력
#분산
print(df1[['중간','기말']].var())
#df1의 '중간'과 '기말'열의 분산 값을 새로운 시리즈(인덱스=각 열의 이름, 값=각 열의 분산 값)로 출력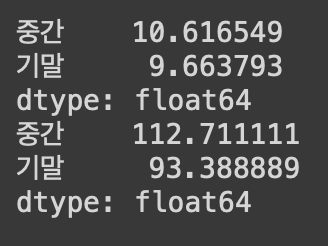
4. 지정한 열에 포함되어 있는 고유한 값의 개수(출현빈도) 세기 : value_counts() 메소드
- 데이터프레임이름['열이름'].value_counts() 형식
df1['퀴즈'].value_counts()
: 데이터프레임 df1의 '퀴즈' 열에서 18점은 3번, 14점과 10점은 2번, 나머지는 각 1번씩 출현한다.
5. 상관계수 구하기: corr() 메소드
- 주어진 두 열 사이의 상관계수 계산
df1[['중간','기말']].corr()
- 열이 주어지지 않는 경우 모든 열에 대해서 상관계수 계산
df1.corr()
#하지만 학번 컬럼이 string(object)형식이기 때문에 오류 발생함
6. 데이터프레임 조작
1. 특정 열을 행 인덱스로 설정: set_index()
- '학번'과 같이 전체 행을 대표하는 열을 인덱스로 지정
- 데이터프레임이름.set_index('열이름') 형식
**지정한 열은 인덱스 역할을 하기때문에 열이름으로 접근 불가능**
df1.set_index('학번')
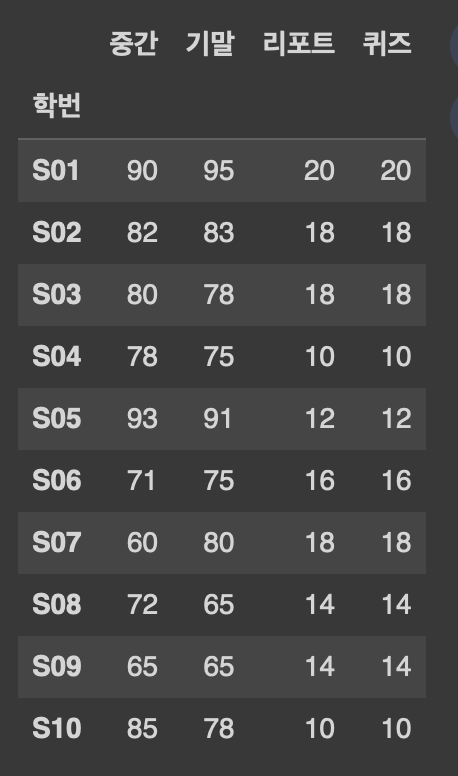
+전체 행을 대표하는 열의 값을 인덱스로 설정하면서 해당 열도 데이터프레임에 남겨두는 방법
: 데이터프레임이름.index = 데이터프레임이름['열이름']
=> 지정된 열의 값은 인덱스명으로 지정되지만 데이터프레임에 그대로 남아있어 열이름으로 접근 가능
df1.index = df1['학번']
df1
** 인덱스 초기화 : 데이터프레임이름.reset_index() **
df1.reset_index(): 정수형 위치 인덱스로 초기화됨 (0~)
2. 원소 선택
- loc: 행인덱스와 열이름을 사용하여 선택, 데이터프레임이름.loc['행인덱스', '열이름']
- iloc: 행번호와 열번호를 사용하여 선택, 데이터프레임이름.iloc[행인덱스번호, 열번호]
df1.set_index('학번', inplace=True)
#'학번' 열을 행 인덱스로 지정
# inplace=True 옵션을 사용하면 df1 = df1.set_index('학번')과 동일한 효과
print(df1.loc['S01','중간'])
print(df1.loc['S02','기말'])
print(df1.iloc[1,0], df1.iloc[1,1], df1.iloc[1,2])
3. 행 선택, 열 선택
- 인덱스명(loc)이나 인덱스번호(iloc)를 사용해서 해당 행 전체를 선택 할 수 있음
df1.loc['S05']
df1.iloc[3]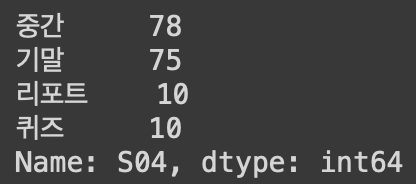
- 특정 열 선택: 데이터프레임이름['열이름'] 또는 데이터프레임.열이름
df1['중간']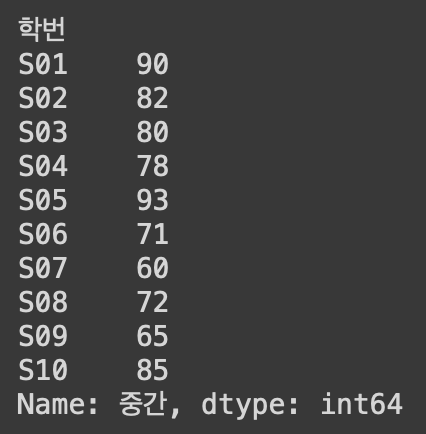
df1.중간
df1[['중간','기말']]
#특정 두 개의 열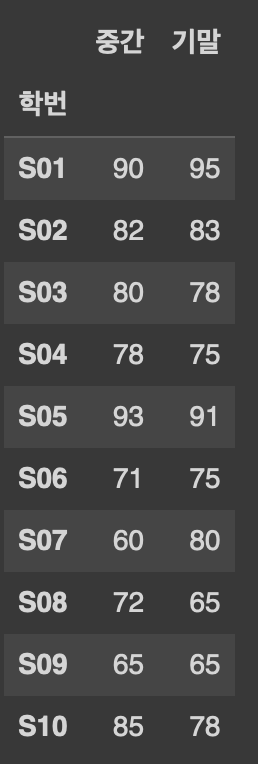
4. 행과 열의 삭제: drop() 메소드
- 기본 설정(axis=0)은 행을 삭제, 열을 삭제할 때는 옵션으로 axis=1 추가
df2 = df1.drop(df1.index[0])
#df1에서 인덱스 0을 가지는 행을 삭제한 데이터프레임을 df2라는 새로운 데이터프레임으로 저장
df3 = df2.drop('퀴즈', axis=1)
#df2에서 '퀴즈'열을 삭제한 데이터프레임을 df3이라는 새로운 데이터프레임으로 저장
df3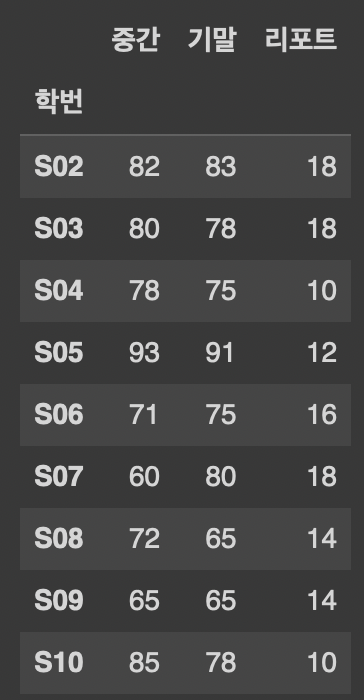
5. 데이터프레임 정렬(행 인덱스 기준): sort_index()
- ascending 옵션을 사용해서 오름차순(ascending=True)/내림차순(ascending=False) 정렬
- 새롭게 정렬된 데이터프레임을 반환함

df2 = df1.sort_index(ascending=False)
#행인덱스('학번') 기준 내림차순 정렬
df2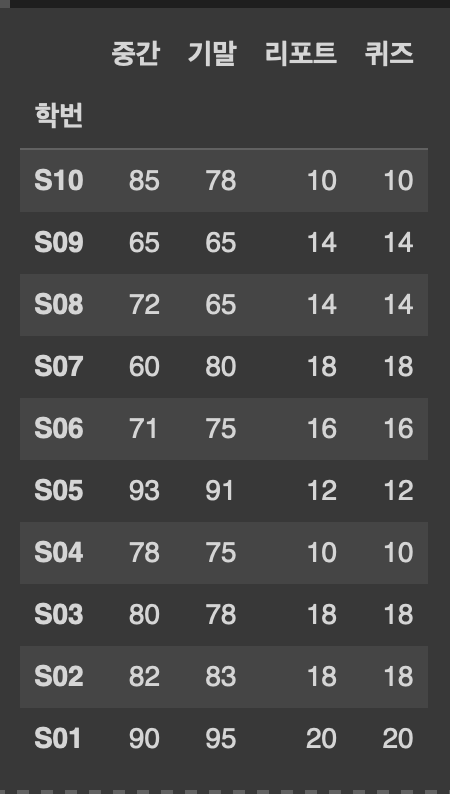
6. 데이터프레임 정렬 (특정 열 기준): sort_values()
- ascending 옵션을 사용해서 오름차순(ascending=True)/내림차순(ascending=False) 정렬
- 새롭게 정렬된 데이터프레임을 반환함
df2 = df1.sort_values(by='기말', ascending=True)
#특정 열('기말') 기준 오름차순 정렬
df2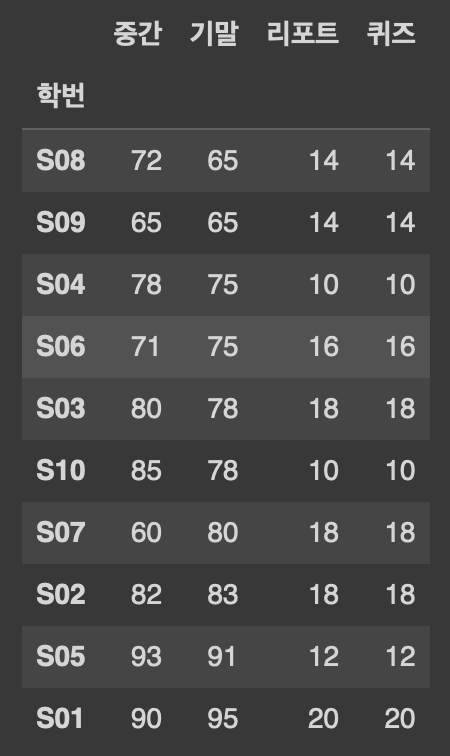
'빅데이터분석기사_실기 > 기초' 카테고리의 다른 글
| 조건에 맞는 데이터 추출하기! (0) | 2024.05.28 |
|---|---|
| 데이터(CSV, EXCEL, HTML) 불러오고 저장하기 (0) | 2024.05.28 |
| 외부 데이터 파일을 불러와 구글 코랩(colab)에서 이용하기 (0) | 2024.05.24 |
| 넘파이(Numpy) 배열 (0) | 2024.05.24 |
| Python Programming 기초 of 기초 (0) | 2024.05.24 |


